








프로젝트 개요
-
구현 목표
강서01 버스 이용자들의 의견을 수집하고, 수집한 만족도 결과를 분석하여 강서01 버스 서비스의 개선 방안을 도출한다.
-
활동 내용
- 1. 에브리타임을 활용한 설문조사 실시 (응답자 수: 111명)
- 2. 수집된 데이터를 정리하고 통계적 분석을 통해 주요 이슈 도출
- 3. 강서01 버스 서비스에 대한 IPA 분석을 통해 핵심 개선 포인트 도출
- Category
- Period
- GitHub
| 설문 데이터 분석 | |
| 2023.03.15.~2023.05.05. | |
| github.com/Isaac-Seungwon/gangseo-01-bus-usage-satisfaction-analysis |
기본 package 설정
# 기본 package 설정
library(tidyverse)
library(tidymodels)
library(rstatix)
library(skimr)
library(FSA)
library(ggpubr)
library(rpart)
library(rpart.plot)
library(caret)
library(tree)
# install.packages("") tidyverse: 데이터 분석과 시각화를 위한 여러 R 패키지를 모아놓은 패키지입니다.
dplyr, ggplot2, tidyr, purrr, stringr 등을 포함하고 있으며, 데이터 전처리, 조작, 시각화 등에 사용합니다.
tidymodels: tidyverse와 마찬가지로 데이터 분석에 필요한 R 패키지를 모아놓은 패키지입니다.
parsnip, recipes, rsample, dials, yardstick 등이 있으며, 머신러닝 모델 제작, 평가, 비교에 사용합니다.
rstatix: 데이터 분석을 위한 통계 분석 도구를 제공하는 패키지입니다.
데이터 분석 결과 요약, 가설 검정, ANOVA, 회귀 분석, 상관 분석 등의 통계 분석에 사용합니다.
skimr: 데이터셋의 요약 통계 정보를 제공하는 패키지입니다.
데이터셋의 변수 유형, 결측치 비율, 이상치 정보 등을 확인하고, 데이터셋의 각 변수별 분포와 기초 통계 정보를 시각화하여 제공합니다.
파이프라인 (%>% 기호)
파이프라인은 이전 코드의 결과를 다음 함수의 첫 번째 인자로 전달하는 역할을 합니다.
왼쪽에 있는 값(데이터)을 오른쪽에 있는 함수에 입력하고, 그 결과를 다시 다음 함수의 입력으로 전달합니다. 이는 함수를 연속적으로 사용하는 것과 유사하며, 파이프라인을 사용하며 가독성을 높이고 간단하게 코드를 작성할 수 있습니다.
데이터 불러오기
# 데이터 불러오기
csi_tb <-read_csv("강서01 버스 이용 만족도 조사.csv",
col_names = T,
locale = locale("ko", encoding = "euc-kr"),
na = ".") %>%
mutate(학생 = factor(학생,
levels = c(1),
labels = c("강서대학생")),
성별 = factor(성별,
levels = c(1:2),
labels = c("남자", "여자")),
학과 = factor(학과,
levels = c(1:8),
labels = c("신학", "사회복지", "G2빅데이터경영",
"상담심리", "간호", "식품영양", "실용음악", "기타")),
학년 = factor(학년,
levels = c(1:4),
labels = c("1학년", "2학년", "3학년", "4학년")),
통학시간 = factor(C1,
levels = c(1:4),
labels = c("30분 이하", "30분 ~ 1시간",
"1시간 ~ 1시간 30분", "2시간 이상")),
통학횟수 = factor(C2,
levels = c(1:5),
labels = c("1일", "2일", "3일", "4일", "5일 이상")),
이용횟수 = factor(D1,
levels = c(1:3),
labels = c("1회 ~ 2회", "3회 ~ 4회", "5회 이상")),
이용시간대 = factor(D2,
levels = c(1:5),
labels = c("오전 9시 전", "오전 10시 ~ 12시",
"오후 13시 ~ 15시", "오후 16시 ~ 18시", "오후 18시 후")),
이용이유 = factor(D3,
levels = c(1:4),
labels = c("강서대학교, 지하철 역 근처에 하차할 수 있어서",
"통학에 가장 적절한 교통수단이어서",
"통학하는데 다른 마땅한 교통 수단이 없어서",
"기타")
)
)
str(csi_tb)
csi_tb
summary(csi_tb) col_names 옵션을 True로 설정하여 열 이름을 사용
locale 옵션을 "ko"와 "euc-kr"로 설정하여 한글 인코딩 방식 채택
na 옵션을 "."으로 설정하여 결측치를 표시
dplyr 패키지, mutate 함수를 사용하여 데이터 프레임의 열을 변형
학부, 학년, 성별 열은 factor 클래스로 변환
각각의 factor 클래스를 정의, levels과 labels를 사용하여 각각의 값을 설정
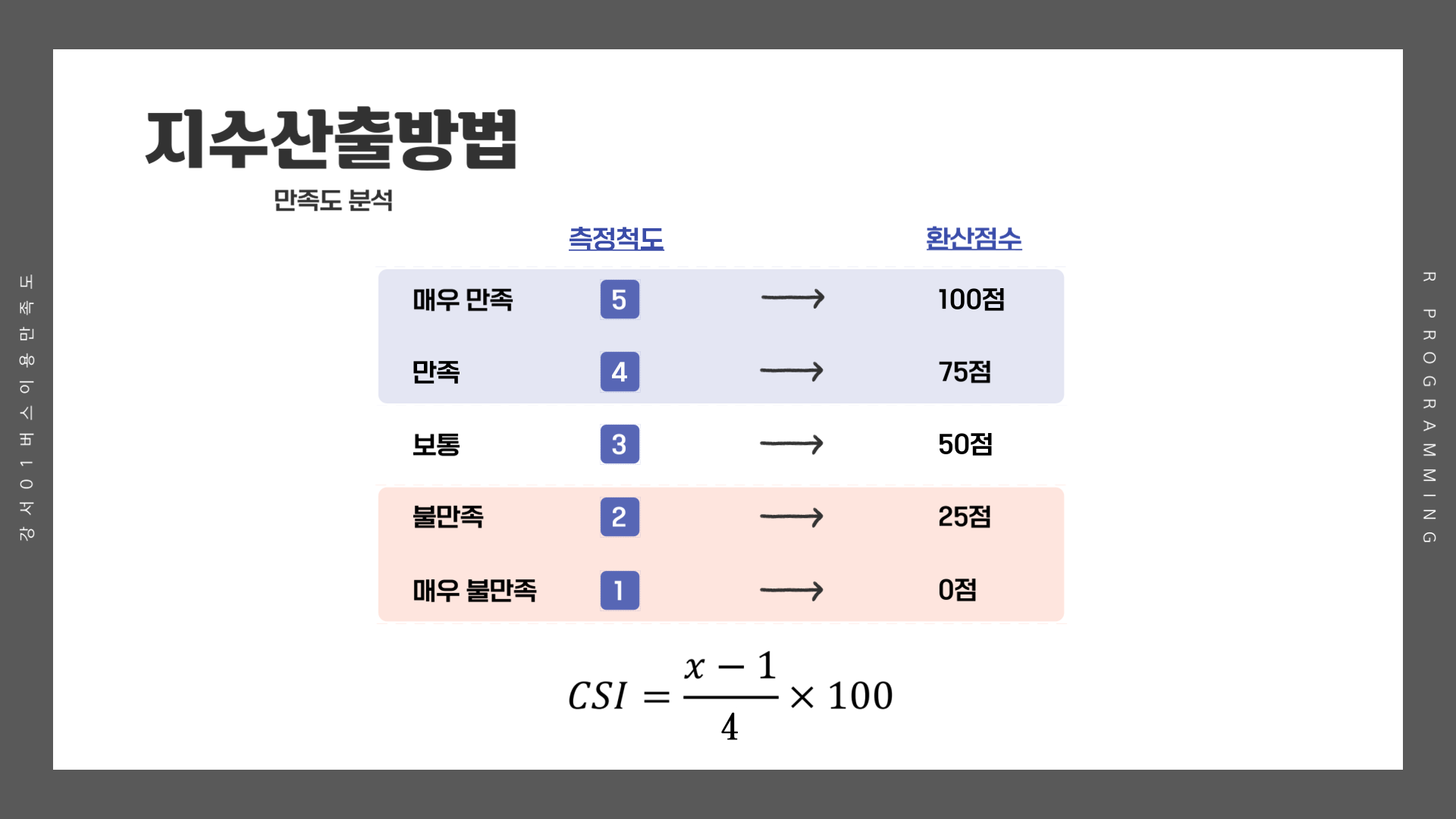
만족도를 100점 만점으로 변환
# 만족도를 100점 만점으로 변환
csi_100_tb <- csi_tb %>%
rowwise() %>%
transmute(학생, 성별, 학과, 학년,
통학시간, 통학횟수, 이용횟수, 이용시간대, 이용이유,
이용환경 = (mean(c(A1, A2, A3))-1)/4*100,
제공서비스 = (mean(c(B1, B2, B3, B4, B5))-1)/4*100,
# 이용환경
배차간격 = (mean(c(A1))-1)/4*100,
쾌적성 = (mean(c(A2))-1)/4*100,
편리성 = (mean(c(A3))-1)/4*100,
# 제공서비스
내부청결성 = (mean(c(B1))-1)/4*100,
외부청결성 = (mean(c(B2))-1)/4*100,
기사님친절성 = (mean(c(B3))-1)/4*100,
정차선신뢰성 = (mean(c(B4))-1)/4*100,
안정성 = (mean(c(B5))-1)/4*100) %>%
as_tibble()
csi_100_tb
str(csi_100_tb) transmute: 데이터셋의 변수를 변환하는 함수로, 새로운 변수를 추가하거나 기존 변수를 수정합니다.
rowwise: '행단위 연산'일때 그룹화를 위해 사용하며, 변수를 행 단위로 계산합니다.
tibble: mutate계산시 list로 생성된 부분을 삭제하여 더욱 직관적이게 합니다.
csi_tb 데이터셋에서 각 항목에 대한 평균값을 100점 만점으로 변환해 csi_100_tb라는 새로운 데이터셋을 만드는 작업
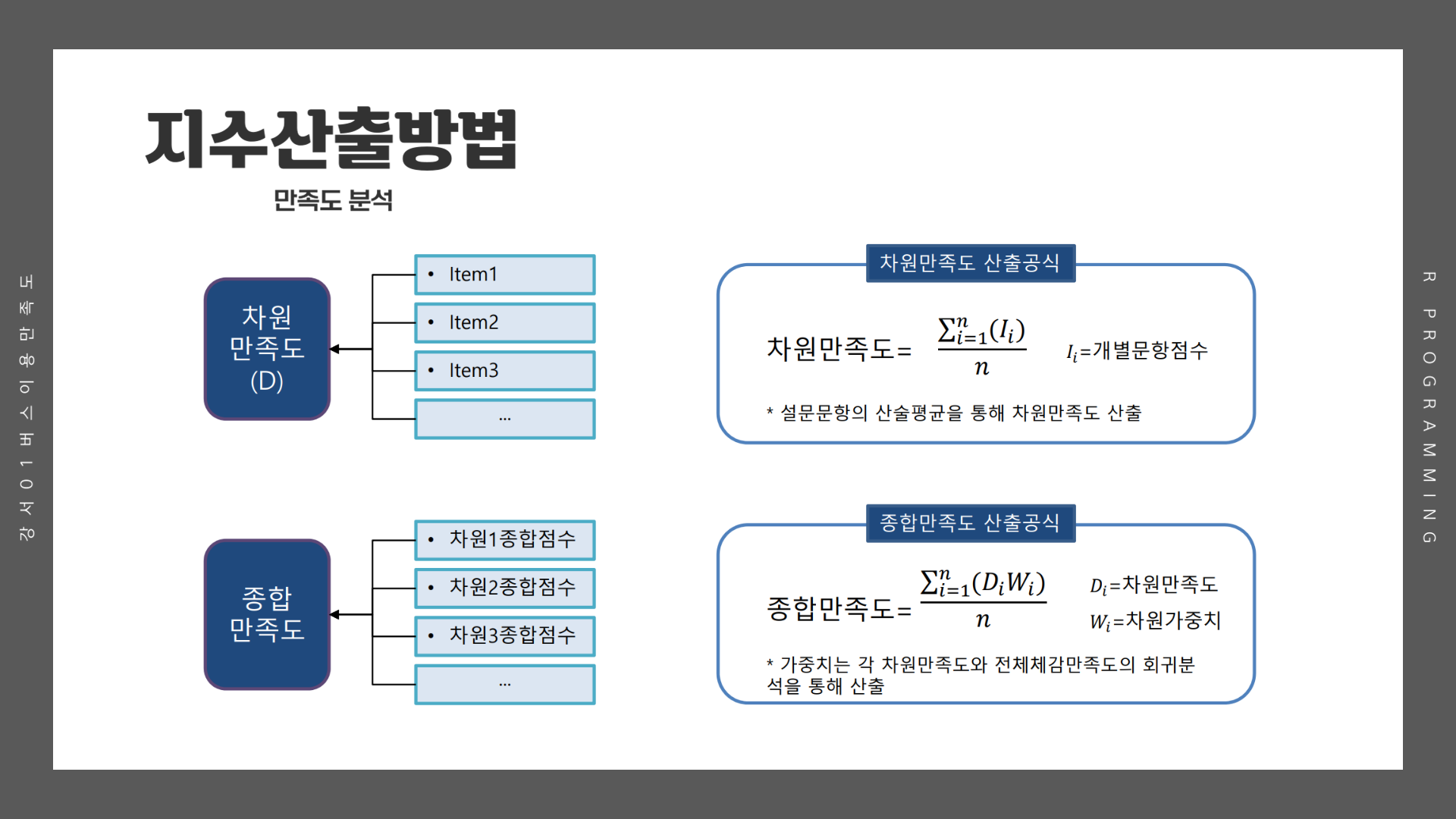
# 종합만족도
csi_total_tb1 <- csi_100_tb %>%
select(이용환경:제공서비스) %>%
rowwise() %>%
mutate(종합만족도 = mean(c(이용환경, 제공서비스))) %>%
as_tibble()
str(csi_total_tb)
# 종합만족도 데이터 추가
csi_100_tb[,20] <- csi_total_tb1[,3]
str(csi_100_tb1)
# 세부만족도
csi_total_tb2 <- csi_100_tb %>%
select(배차간격:안정성) %>%
rowwise() %>%
mutate(세부만족도 = mean(c(배차간격, 쾌적성, 편리성,
내부청결성, 외부청결성, 기사님친절성, 정차선신뢰성, 안정성))) %>%
as_tibble()
str(csi_total_tb)
# 세부만족도 데이터 추가
csi_100_tb[,21] <- csi_total_tb2[,9]
str(csi_100_tb2) csi_100_tb 데이터셋 변수들을 이용하여 종합만족도를 계산
select() 함수를 이용하여 변수 선택
rowwise() 함수를 이용하여 행별로 계산
mutate() 함수를 이용하여 종합만족도 변수 계산
filter(), select() 함수를 이용하여 해당 변수와 가중치를 선택한 후, * 연산자로 가중합을 계산
계산 결과는 unnest() 함수와 rename() 함수를 이용하여 종합만족도만 남긴 후, dbl 형식으로 처리
만족도 분석 결과 출력
# 만족도 분석 결과 출력
# 만족도 ~ 전체 학생
df <- Summarize(이용환경 ~ 학생, csi_100_tb)
df[2,] <- Summarize(제공서비스 ~ 학생, csi_100_tb)
df[3,] <- Summarize(종합만족도 ~ 학생, csi_100_tb)
df[4,] <- Summarize(배차간격 ~ 학생, csi_100_tb)
df[5,] <- Summarize(쾌적성 ~ 학생, csi_100_tb)
df[6,] <- Summarize(편리성 ~ 학생, csi_100_tb)
df[7,] <- Summarize(내부청결성 ~ 학생, csi_100_tb)
df[8,] <- Summarize(외부청결성 ~ 학생, csi_100_tb)
df[9,] <- Summarize(기사님친절성 ~ 학생, csi_100_tb)
df[10,] <- Summarize(정차선신뢰성 ~ 학생, csi_100_tb)
df[11,] <- Summarize(안정성 ~ 학생, csi_100_tb)
write_excel_csv(df, file="1-1. 종합 강서01 버스 이용 만족도.csv", col_names = T)
# 만족도 ~ 성별
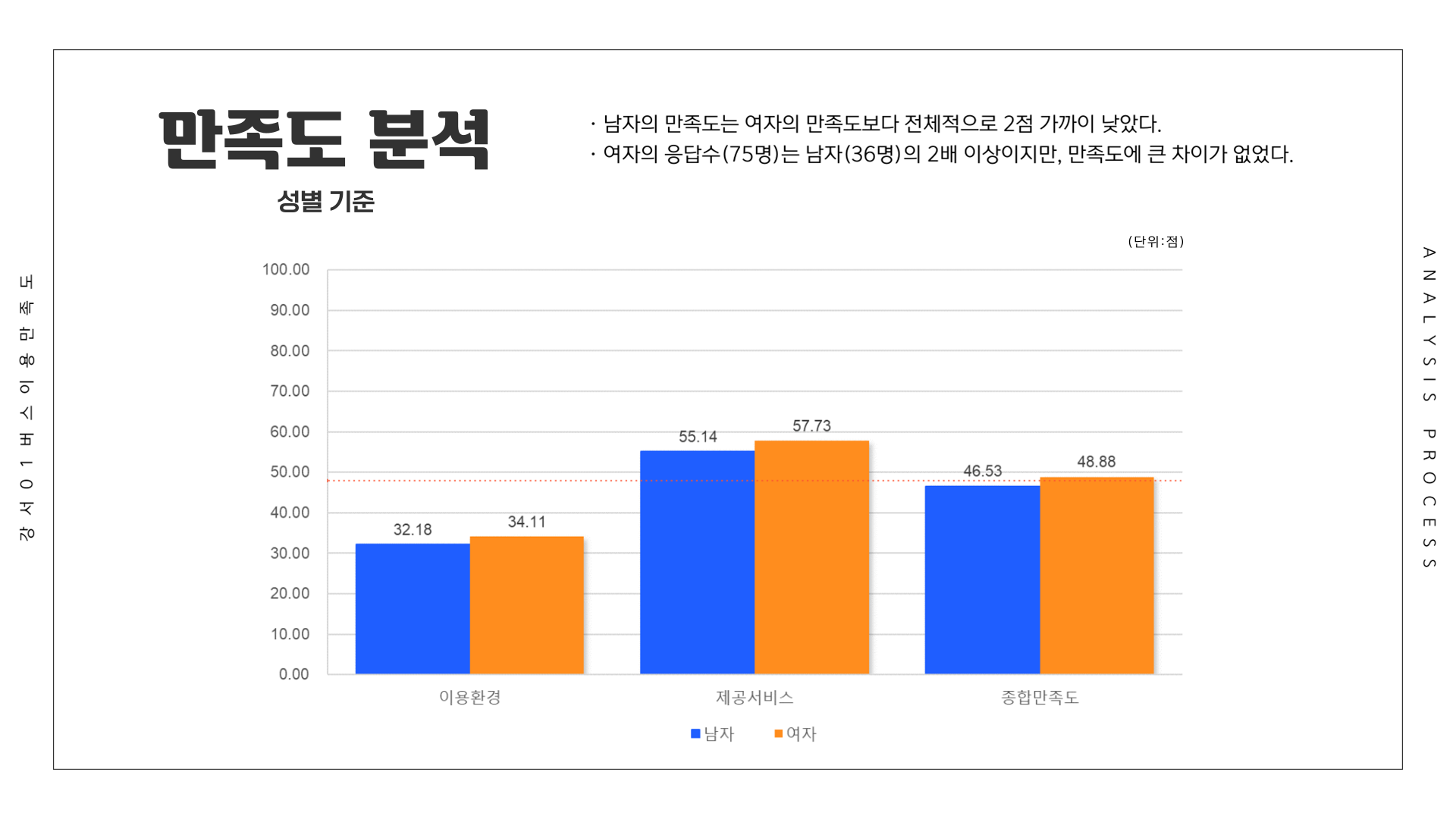
df <- Summarize(이용환경 ~ 성별, csi_100_tb)
df[3:4,] <- Summarize(제공서비스 ~ 성별, csi_100_tb)
df[5:6,] <- Summarize(종합만족도 ~ 성별, csi_100_tb)
df[7:8,] <- Summarize(배차간격 ~ 성별, csi_100_tb)
df[9:10,] <- Summarize(쾌적성 ~ 성별, csi_100_tb)
df[11:12,] <- Summarize(편리성 ~ 성별, csi_100_tb)
df[13:14,] <- Summarize(내부청결성 ~ 성별, csi_100_tb)
df[15:16,] <- Summarize(외부청결성 ~ 성별, csi_100_tb)
df[17:18,] <- Summarize(기사님친절성 ~ 성별, csi_100_tb)
df[19:20,] <- Summarize(정차선신뢰성 ~ 성별, csi_100_tb)
df[21:22,] <- Summarize(안정성 ~ 성별, csi_100_tb)
write_excel_csv(df, file="1-2. 성별별 강서01 버스 이용 만족도.csv", col_names = T)
# 만족도 ~ 학과
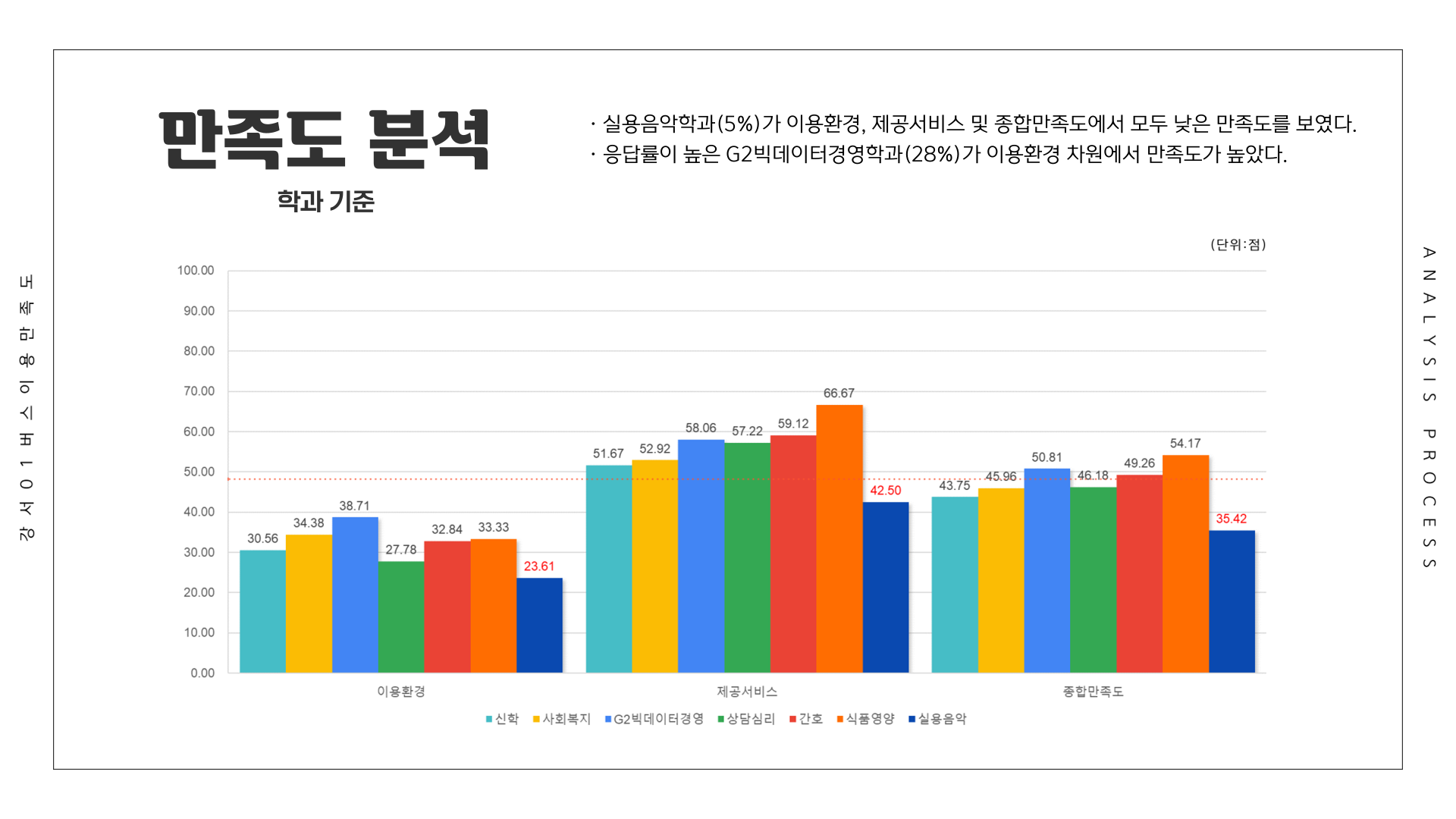
df <- Summarize(이용환경 ~ 학과, csi_100_tb)
df[8:14,] <- Summarize(제공서비스 ~ 학과, csi_100_tb)
df[15:21,] <- Summarize(종합만족도 ~ 학과, csi_100_tb)
df[22:28,] <- Summarize(배차간격 ~ 학과, csi_100_tb)
df[29:35,] <- Summarize(쾌적성 ~ 학과, csi_100_tb)
df[36:42,] <- Summarize(편리성 ~ 학과, csi_100_tb)
df[43:49,] <- Summarize(내부청결성 ~ 학과, csi_100_tb)
df[50:56,] <- Summarize(외부청결성 ~ 학과, csi_100_tb)
df[57:63,] <- Summarize(기사님친절성 ~ 학과, csi_100_tb)
df[64:70,] <- Summarize(정차선신뢰성 ~ 학과, csi_100_tb)
df[71:77,] <- Summarize(안정성 ~ 학과, csi_100_tb)
write_excel_csv(df, file="1-3. 학과별 강서01 버스 이용 만족도.csv", col_names = T)
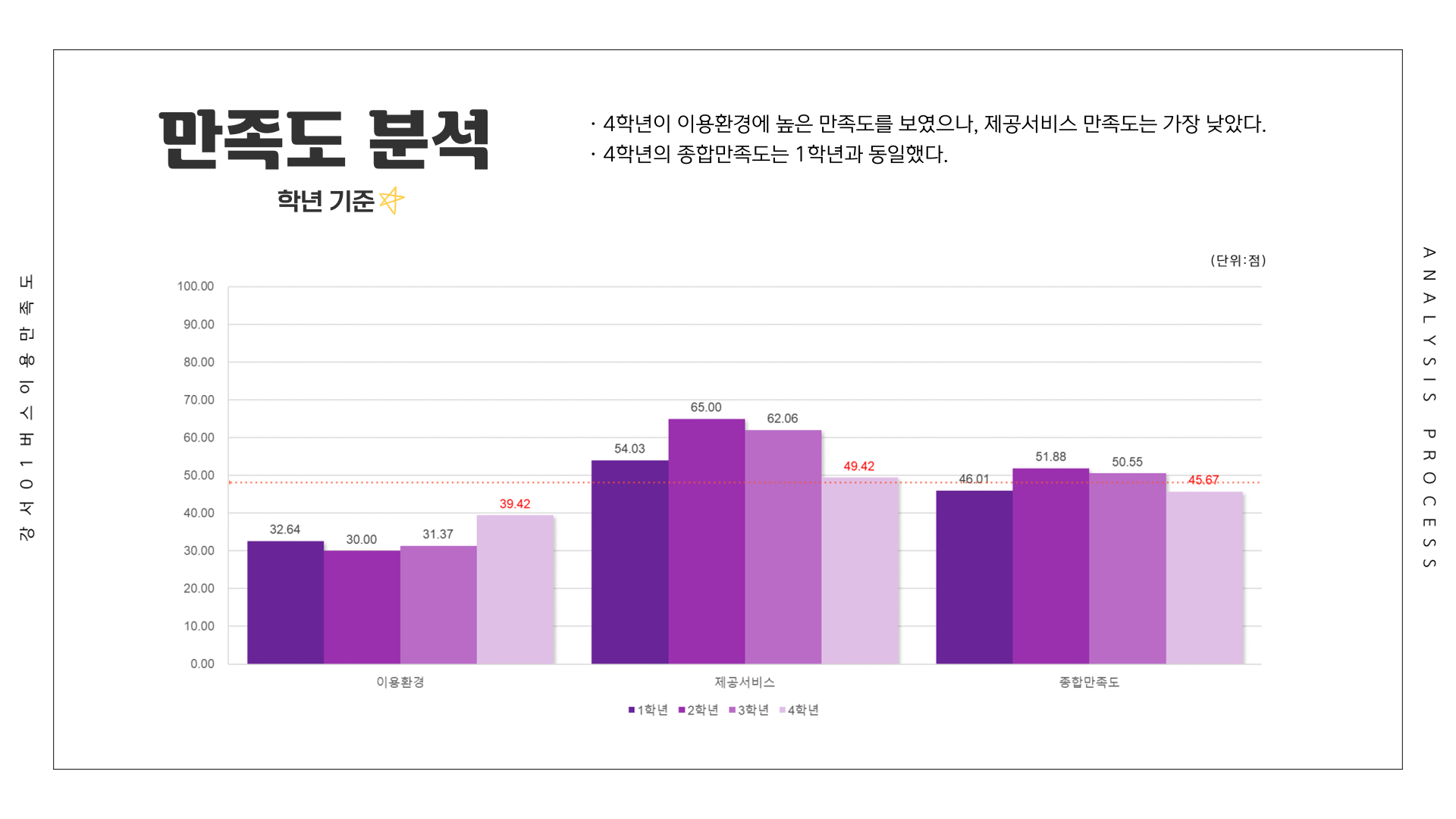
# 만족도 ~ 학년
df <- Summarize(이용환경 ~ 학년, csi_100_tb)
df[5:8,] <- Summarize(제공서비스 ~ 학년, csi_100_tb)
df[9:12,] <- Summarize(종합만족도 ~ 학년, csi_100_tb)
df[13:16,] <- Summarize(배차간격 ~ 학년, csi_100_tb)
df[17:20,] <- Summarize(쾌적성 ~ 학년, csi_100_tb)
df[21:24,] <- Summarize(편리성 ~ 학년, csi_100_tb)
df[25:28,] <- Summarize(내부청결성 ~ 학년, csi_100_tb)
df[29:32,] <- Summarize(외부청결성 ~ 학년, csi_100_tb)
df[33:36,] <- Summarize(기사님친절성 ~ 학년, csi_100_tb)
df[37:40,] <- Summarize(정차선신뢰성 ~ 학년, csi_100_tb)
df[41:44,] <- Summarize(안정성 ~ 학년, csi_100_tb)
write_excel_csv(df, file="1-4. 학년별 강서01 버스 이용 만족도.csv", col_names = T)
# 만족도 ~ 통학시간
df <- Summarize(이용환경 ~ 통학시간, csi_100_tb)
df[5:8,] <- Summarize(제공서비스 ~ 통학시간, csi_100_tb)
df[9:12,] <- Summarize(종합만족도 ~ 통학시간, csi_100_tb)
df[13:16,] <- Summarize(배차간격 ~ 통학시간, csi_100_tb)
df[17:20,] <- Summarize(쾌적성 ~ 통학시간, csi_100_tb)
df[21:24,] <- Summarize(편리성 ~ 통학시간, csi_100_tb)
df[25:28,] <- Summarize(내부청결성 ~ 통학시간, csi_100_tb)
df[29:32,] <- Summarize(외부청결성 ~ 통학시간, csi_100_tb)
df[33:36,] <- Summarize(기사님친절성 ~ 통학시간, csi_100_tb)
df[37:40,] <- Summarize(정차선신뢰성 ~ 통학시간, csi_100_tb)
df[41:44,] <- Summarize(안정성 ~ 통학시간, csi_100_tb)
write_excel_csv(df, file="1-5. 통학시간별 강서01 버스 이용 만족도.csv", col_names = T)
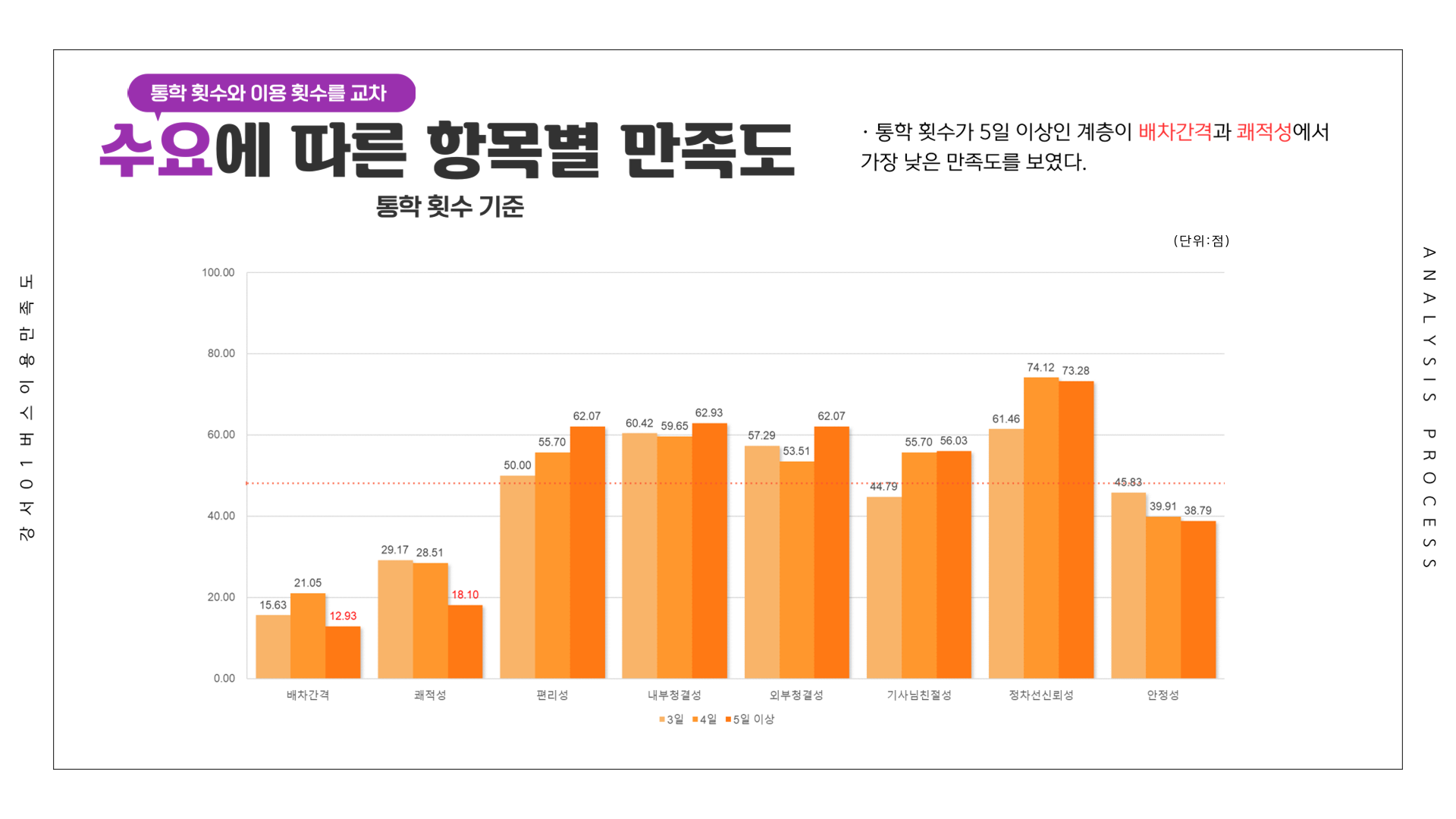
# 만족도 ~ 통학횟수
df <- Summarize(이용환경 ~ 통학횟수, csi_100_tb)
df[5:8,] <- Summarize(제공서비스 ~ 통학횟수, csi_100_tb)
df[9:12,] <- Summarize(종합만족도 ~ 통학횟수, csi_100_tb)
df[13:16,] <- Summarize(배차간격 ~ 통학횟수, csi_100_tb)
df[17:20,] <- Summarize(쾌적성 ~ 통학횟수, csi_100_tb)
df[21:24,] <- Summarize(편리성 ~ 통학횟수, csi_100_tb)
df[25:28,] <- Summarize(내부청결성 ~ 통학횟수, csi_100_tb)
df[29:32,] <- Summarize(외부청결성 ~ 통학횟수, csi_100_tb)
df[33:36,] <- Summarize(기사님친절성 ~ 통학횟수, csi_100_tb)
df[37:40,] <- Summarize(정차선신뢰성 ~ 통학횟수, csi_100_tb)
df[41:44,] <- Summarize(안정성 ~ 통학횟수, csi_100_tb)
write_excel_csv(df, file="1-6. 통학횟수별 강서01 버스 이용 만족도.csv", col_names = T)
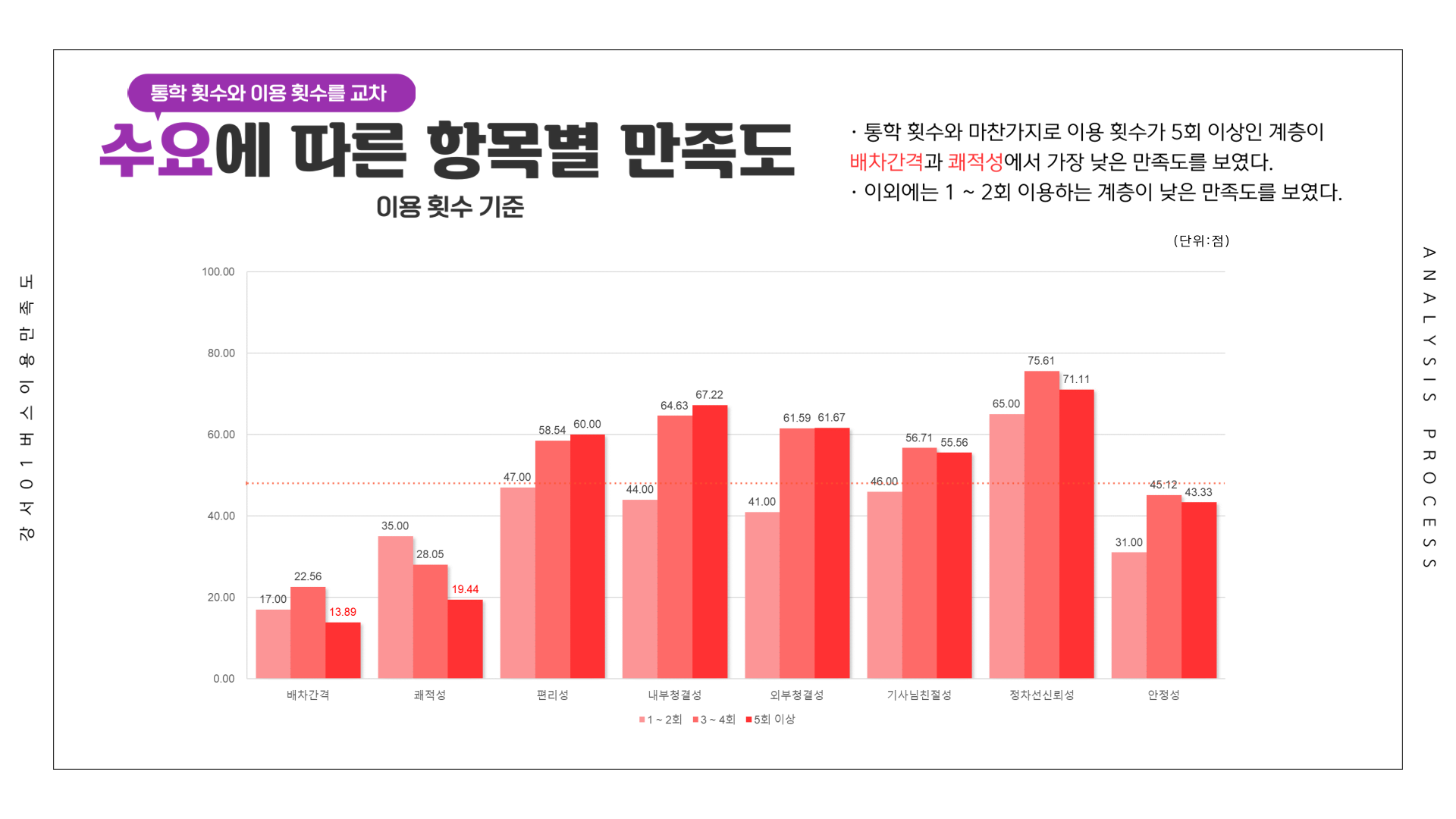
# 만족도 ~ 이용횟수
df <- Summarize(이용환경 ~ 이용횟수, csi_100_tb)
df[4:6,] <- Summarize(제공서비스 ~ 이용횟수, csi_100_tb)
df[7:9,] <- Summarize(종합만족도 ~ 이용횟수, csi_100_tb)
df[10:12,] <- Summarize(배차간격 ~ 이용횟수, csi_100_tb)
df[13:15,] <- Summarize(쾌적성 ~ 이용횟수, csi_100_tb)
df[16:18,] <- Summarize(편리성 ~ 이용횟수, csi_100_tb)
df[19:21,] <- Summarize(내부청결성 ~ 이용횟수, csi_100_tb)
df[22:24,] <- Summarize(외부청결성 ~ 이용횟수, csi_100_tb)
df[25:27,] <- Summarize(기사님친절성 ~ 이용횟수, csi_100_tb)
df[28:30,] <- Summarize(정차선신뢰성 ~ 이용횟수, csi_100_tb)
df[31:33,] <- Summarize(안정성 ~ 이용횟수, csi_100_tb)
write_excel_csv(df, file="1-7. 이용횟수별 강서01 버스 이용 만족도.csv", col_names = T)
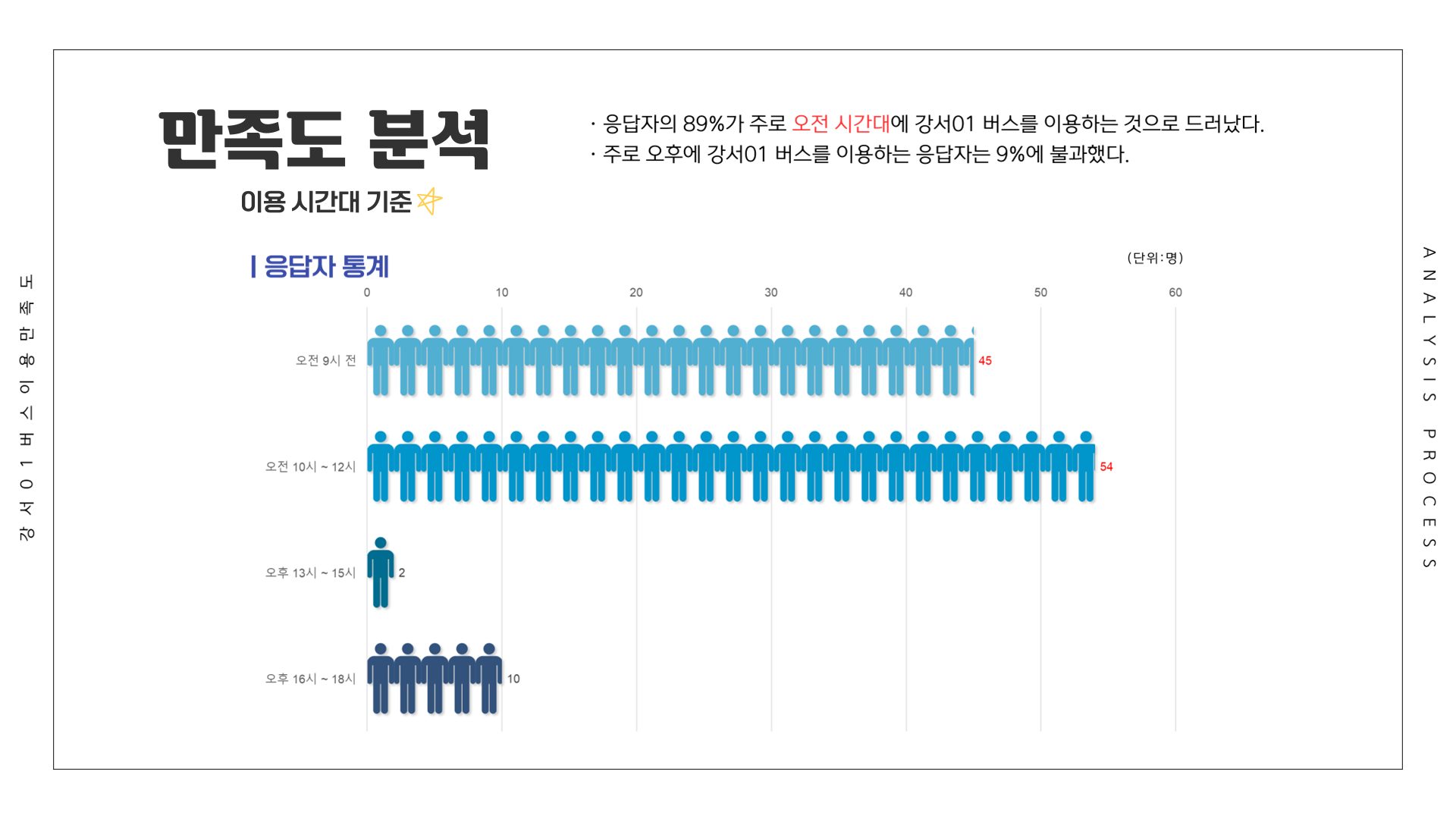
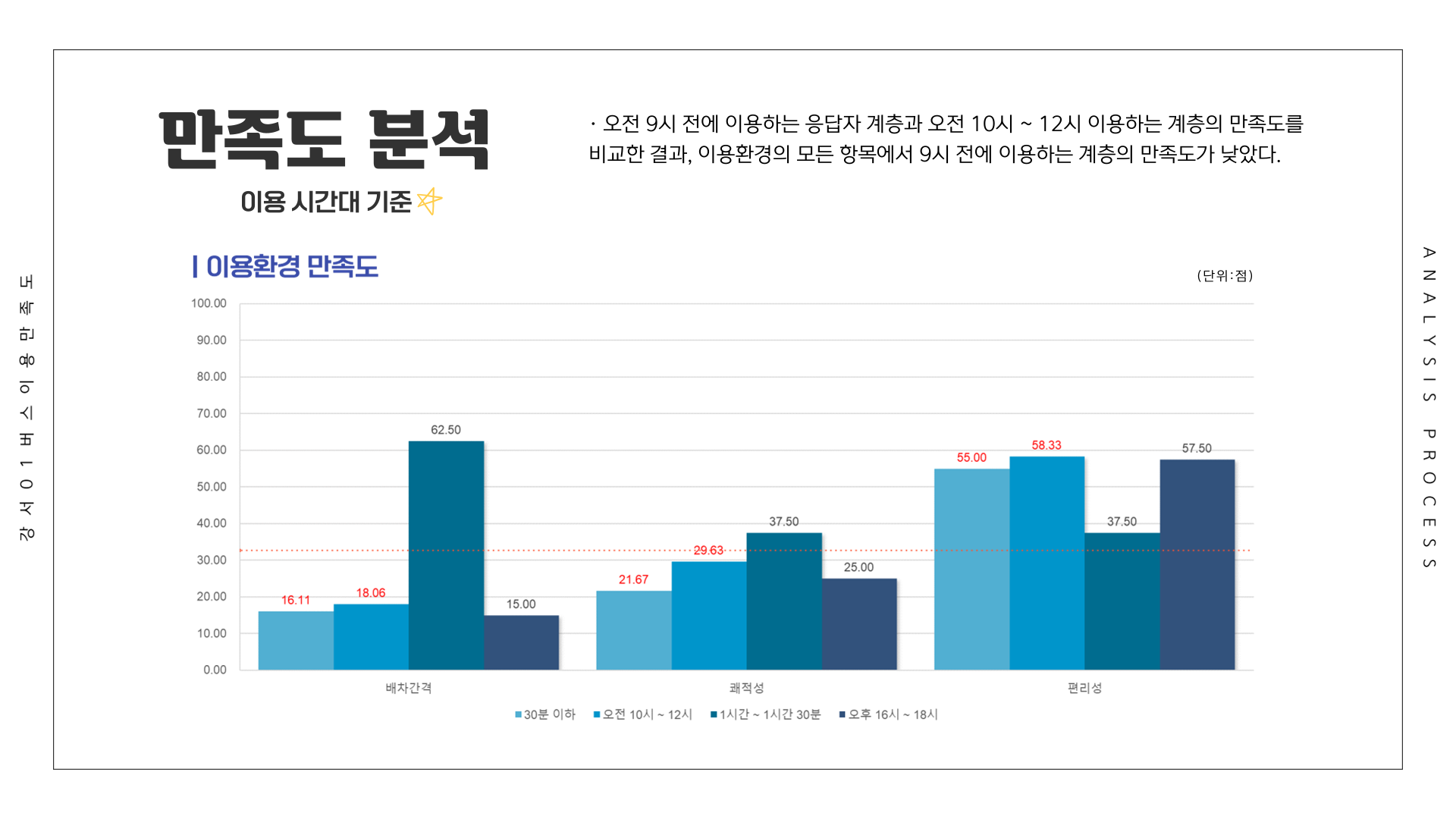
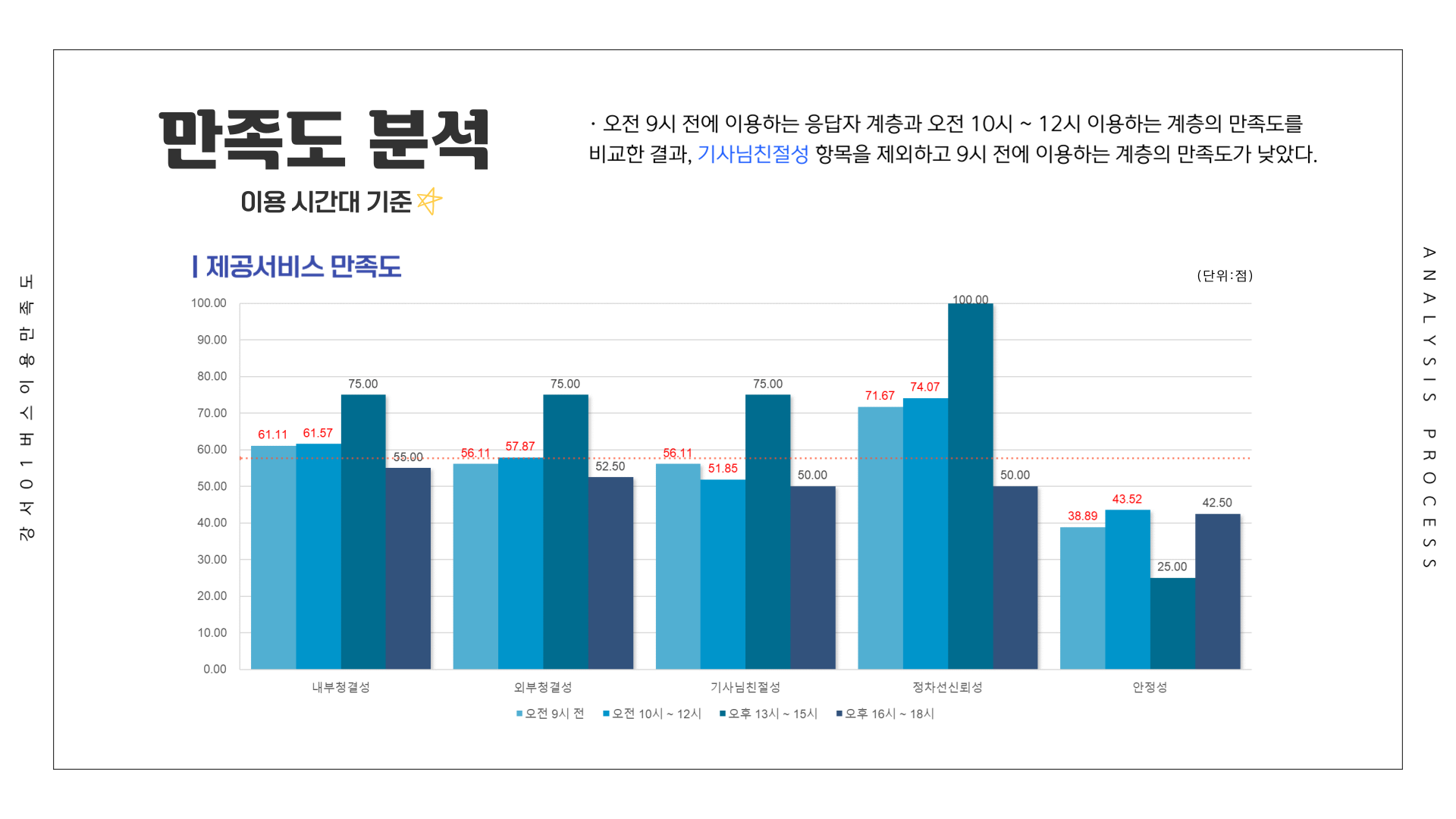
# 만족도 ~ 이용시간대
df <- Summarize(이용환경 ~ 이용시간대, csi_100_tb)
df[5:8,] <- Summarize(제공서비스 ~ 이용시간대, csi_100_tb)
df[9:12,] <- Summarize(종합만족도 ~ 이용시간대, csi_100_tb)
df[13:16,] <- Summarize(배차간격 ~ 이용시간대, csi_100_tb)
df[17:20,] <- Summarize(쾌적성 ~ 이용시간대, csi_100_tb)
df[21:24,] <- Summarize(편리성 ~ 이용시간대, csi_100_tb)
df[25:28,] <- Summarize(내부청결성 ~ 이용시간대, csi_100_tb)
df[29:32,] <- Summarize(외부청결성 ~ 이용시간대, csi_100_tb)
df[33:36,] <- Summarize(기사님친절성 ~ 이용시간대, csi_100_tb)
df[37:40,] <- Summarize(정차선신뢰성 ~ 이용시간대, csi_100_tb)
df[41:44,] <- Summarize(안정성 ~ 이용시간대, csi_100_tb)
write_excel_csv(df, file="1-8. 이용시간대별 강서01 버스 이용 만족도.csv", col_names = T)
# 만족도 ~ 이용이유
df <- Summarize(이용환경 ~ 이용이유, csi_100_tb)
df[4:6,] <- Summarize(제공서비스 ~ 이용이유, csi_100_tb)
df[7:9,] <- Summarize(종합만족도 ~ 이용이유, csi_100_tb)
df[10:12,] <- Summarize(배차간격 ~ 이용이유, csi_100_tb)
df[13:15,] <- Summarize(쾌적성 ~ 이용이유, csi_100_tb)
df[16:18,] <- Summarize(편리성 ~ 이용이유, csi_100_tb)
df[19:21,] <- Summarize(내부청결성 ~ 이용이유, csi_100_tb)
df[22:24,] <- Summarize(외부청결성 ~ 이용이유, csi_100_tb)
df[25:27,] <- Summarize(기사님친절성 ~ 이용이유, csi_100_tb)
df[28:30,] <- Summarize(정차선신뢰성 ~ 이용이유, csi_100_tb)
df[31:33,] <- Summarize(안정성 ~ 이용이유, csi_100_tb)
write_excel_csv(df, file="1-9. 이용이유별 강서01 버스 이용 만족도.csv", col_names = T)
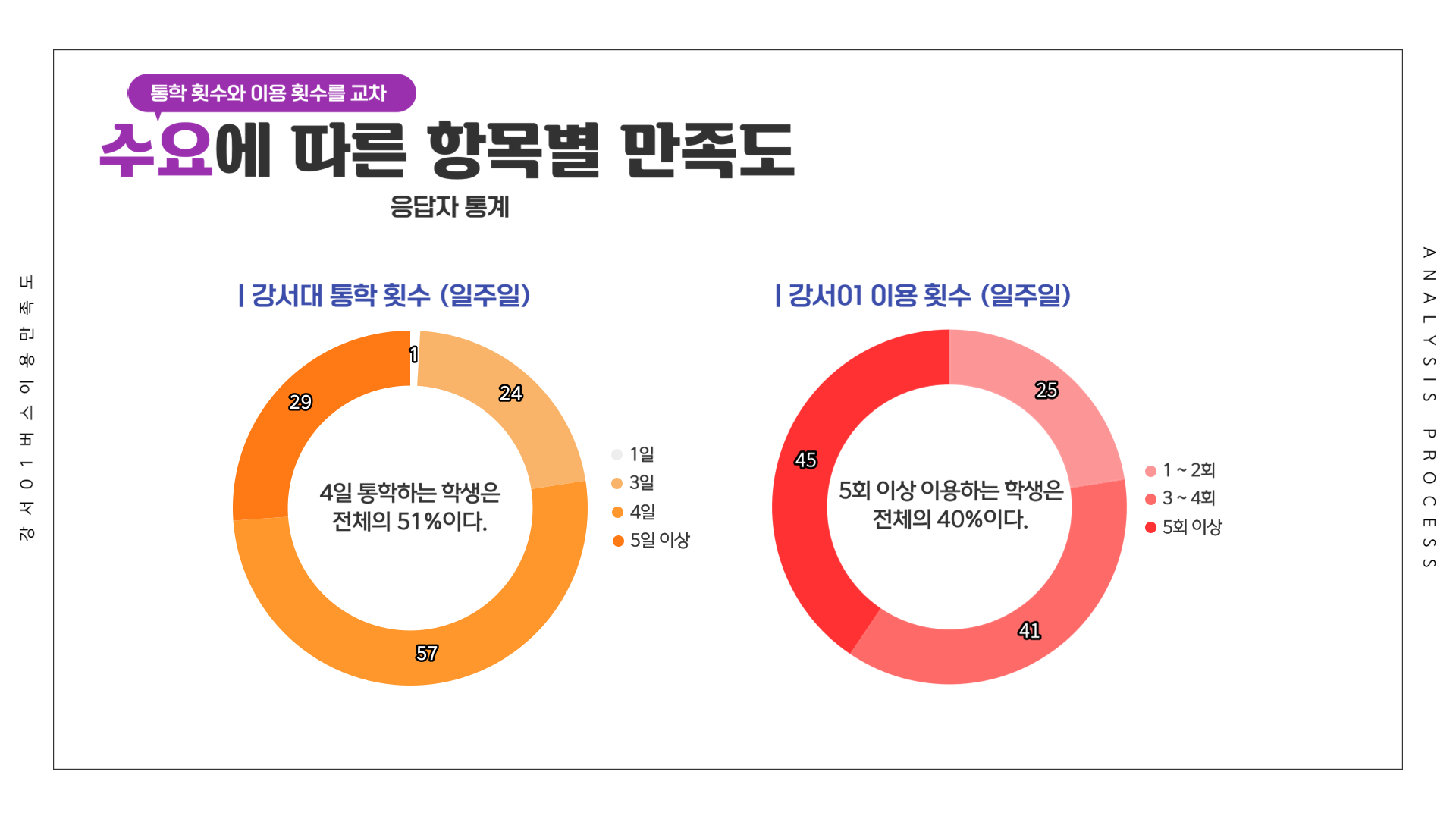
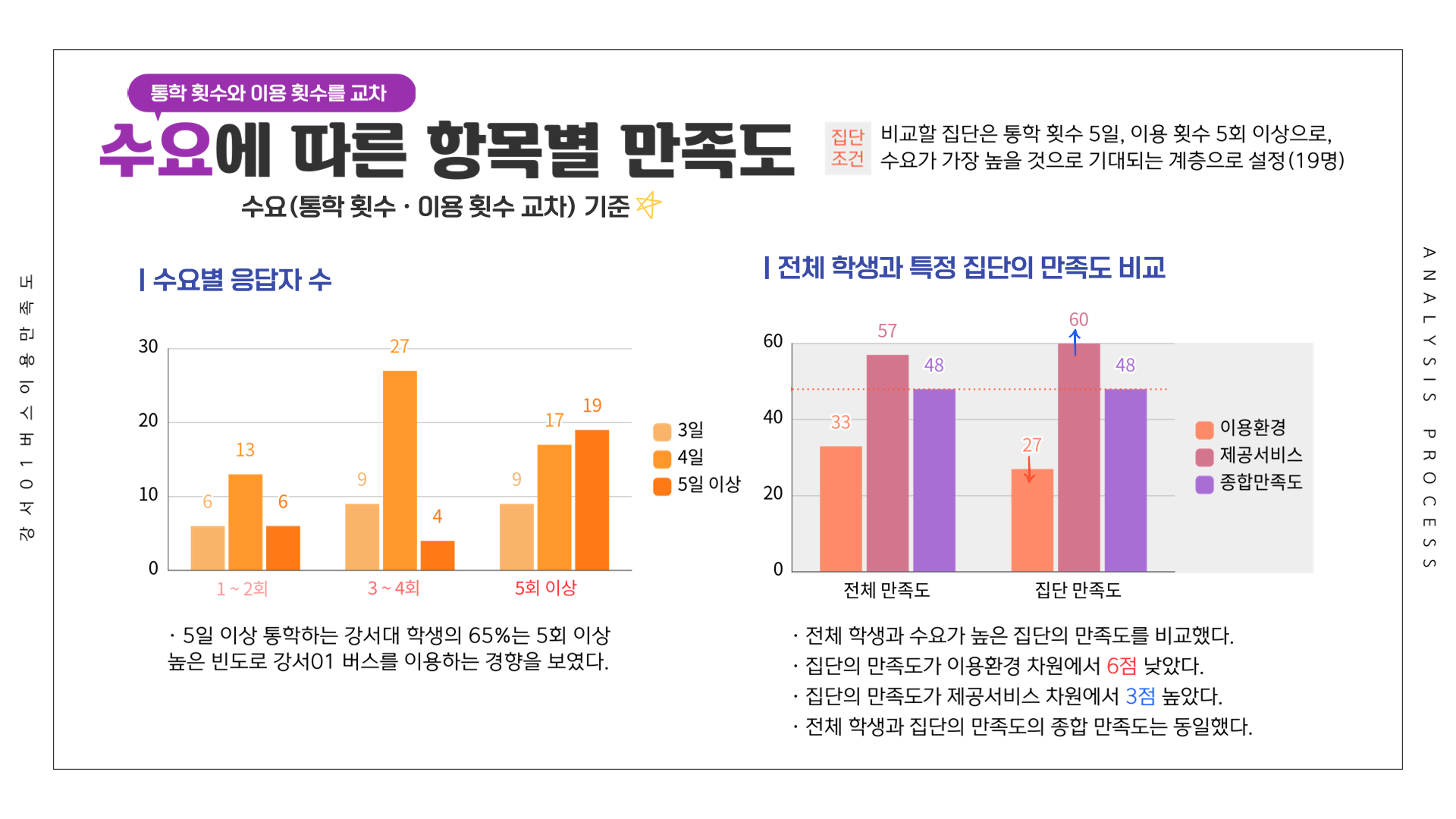
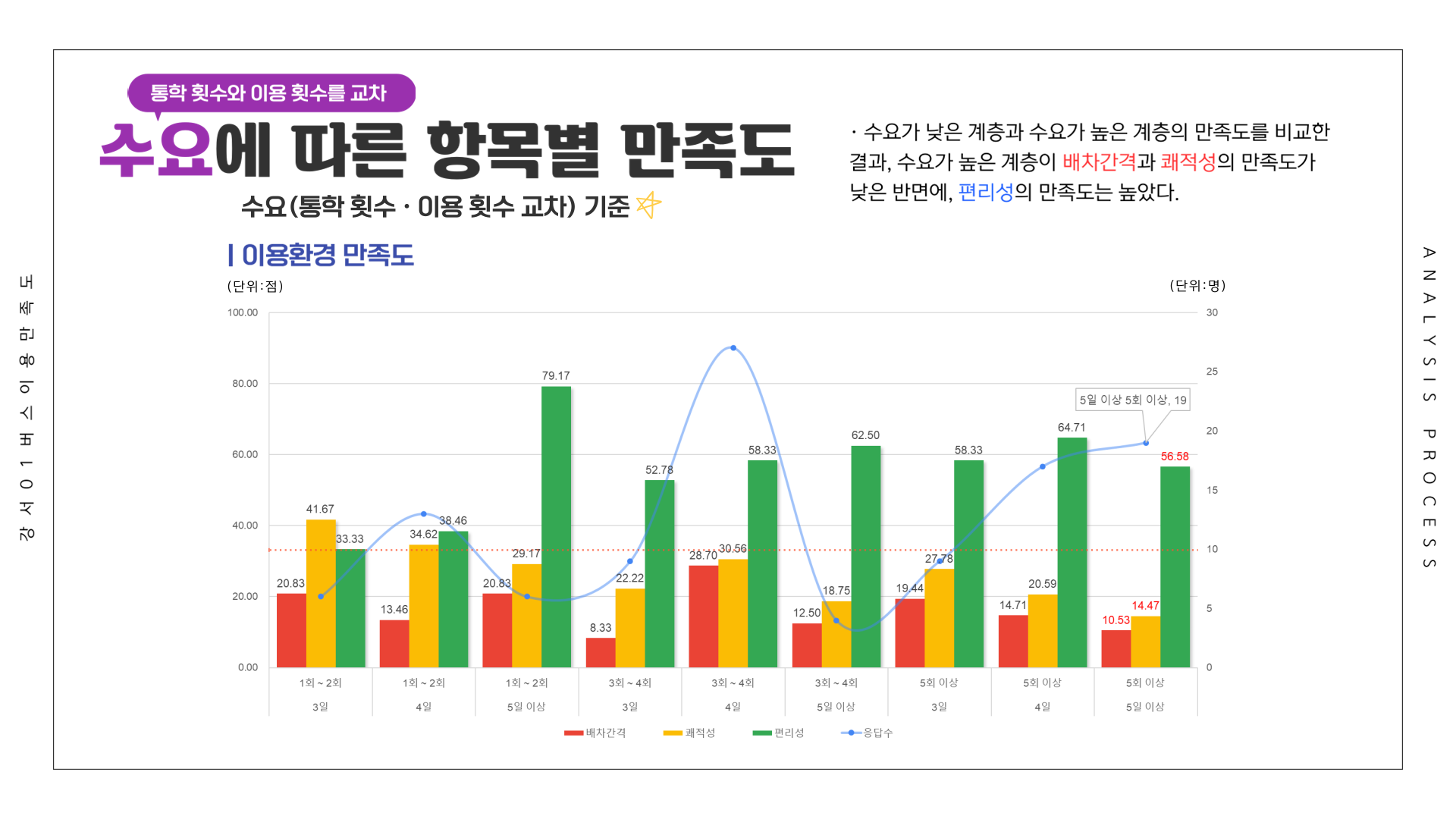
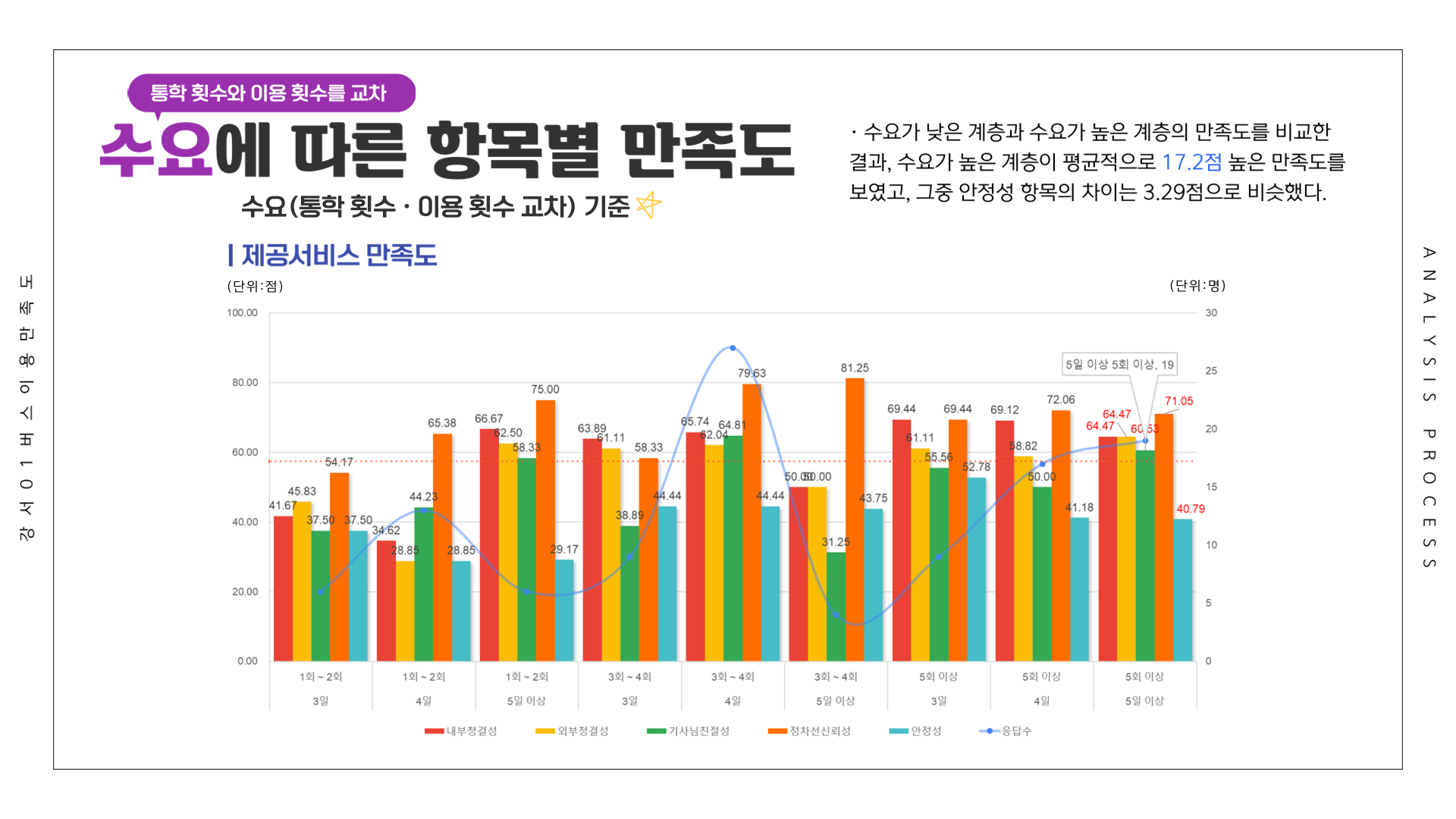
# 만족도 ~ 통학횟수 + 이용횟수 (교차)
df <- Summarize(이용환경 ~ 통학횟수 + 이용횟수, csi_100_tb)
df[11:20,] <- Summarize(제공서비스 ~ 통학횟수 + 이용횟수, csi_100_tb)
df[21:30,] <- Summarize(종합만족도 ~ 통학횟수 + 이용횟수, csi_100_tb)
df[31:40,] <- Summarize(배차간격 ~ 통학횟수 + 이용횟수, csi_100_tb)
df[41:50,] <- Summarize(쾌적성 ~ 통학횟수 + 이용횟수, csi_100_tb)
df[51:60,] <- Summarize(편리성 ~ 통학횟수 + 이용횟수, csi_100_tb)
df[61:70,] <- Summarize(내부청결성 ~ 통학횟수 + 이용횟수, csi_100_tb)
df[71:80,] <- Summarize(외부청결성 ~ 통학횟수 + 이용횟수, csi_100_tb)
df[81:90,] <- Summarize(기사님친절성 ~ 통학횟수 + 이용횟수, csi_100_tb)
df[91:100,] <- Summarize(정차선신뢰성 ~ 통학횟수 + 이용횟수, csi_100_tb)
df[101:110,] <- Summarize(안정성 ~ 통학횟수 + 이용횟수, csi_100_tb)
write_excel_csv(df, file="1-10. 수요별 (통학횟수, 이용횟수) 강서01 버스 이용 만족도.csv", col_names = T) 만족도 그래프
# 만족도 그래프
ggbarplot(csi_100_tb,
x = "학과",
y = "이용환경",
add = c("mean_sd"),
fill = "학과",
ylim = c(0,100),
legend = "right")
ggbarplot(csi_100_tb,
x = "학과",
y = "제공서비스",
add = c("mean_sd"),
fill = "학과",
ylim = c(0,100),
legend = "right")
ggbarplot(csi_100_tb,
x = "학과",
y = "종합만족도",
add = c("mean_sd"),
fill = "학과",
ylim = c(0,100),
legend = "right") 응답자 특성 출력
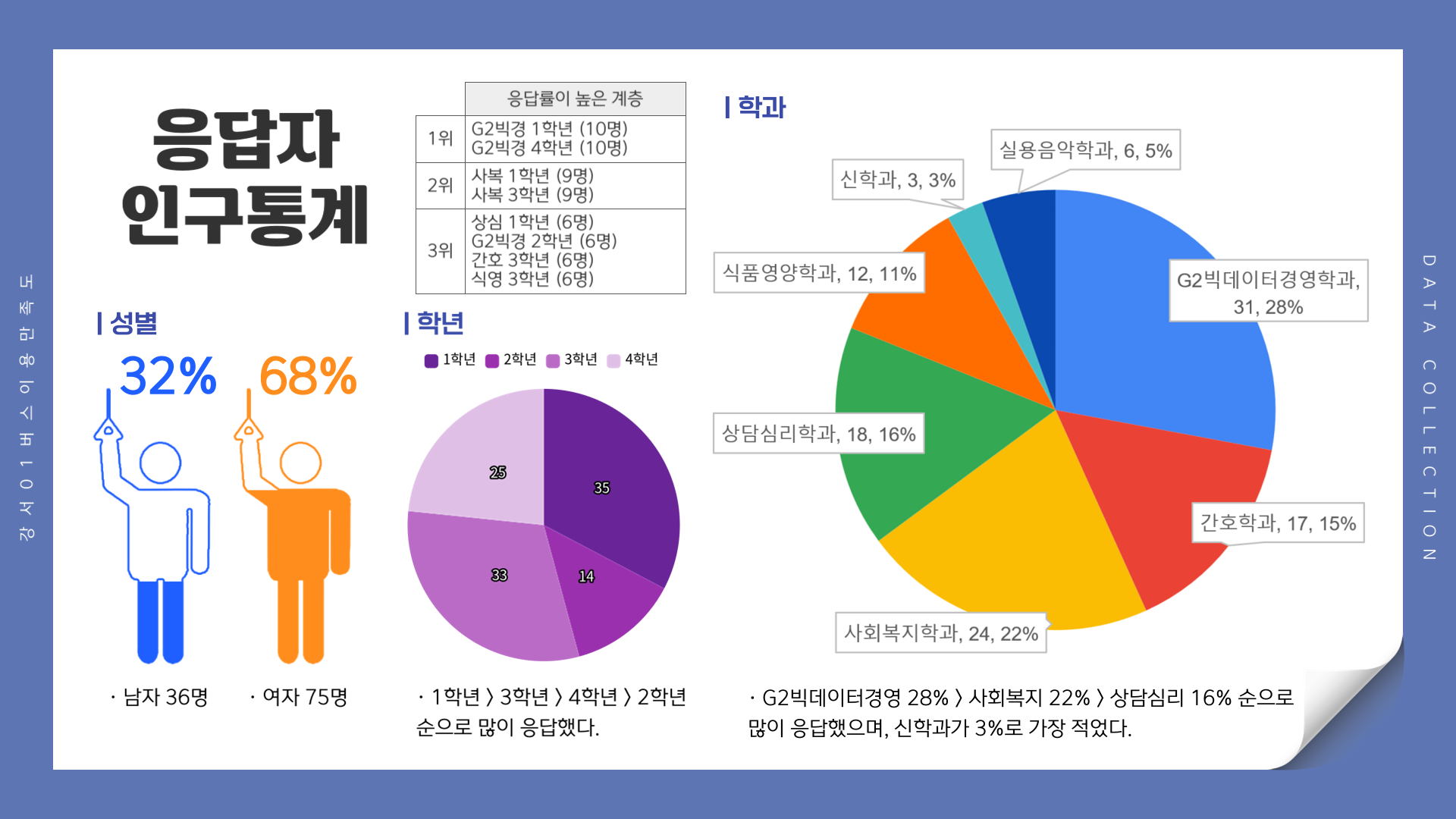
# 응답자 특성 출력
# 성별
csi_100_tb %>%
freq_table(성별) %>%
write_excel_csv("2-1. 응답자_성별.csv", col_names = T)
# 학과
csi_100_tb %>%
freq_table(학과) %>%
write_excel_csv("2-2. 응답자_학부.csv", col_names = T)
# 학년
csi_100_tb %>%
freq_table(학년) %>%
write_excel_csv("2-3. 응답자_학년.csv", col_names = T)
# 통학시간+통학횟수
csi_100_tb %>%
freq_table(통학시간, 통학횟수) %>%
write_excel_csv("2-4. 응답자_통학시간_통학횟수.csv", col_names = T)
# 이용횟수+이용시간대
csi_100_tb %>%
freq_table(이용횟수, 이용시간대) %>%
write_excel_csv("2-5. 응답자_이용횟수_이용시간대.csv", col_names = T)
# 통학횟수+이용횟수
csi_100_tb %>%
freq_table(통학횟수, 이용횟수) %>%
write_excel_csv("2-6. 응답자_통학횟수_이용횟수.csv", col_names = T)
# 학과+학년
csi_100_tb %>%
freq_table(학과, 학년) %>%
write_excel_csv("2-7. 응답자_학과, 학년.csv", col_names = T)
# 성별+학과+학년
csi_100_tb %>%
freq_table(성별, 학과, 학년) %>%
write_excel_csv("2-8. 응답자_성별, 학과, 학년.csv", col_names = T) IPA 중요도 계산
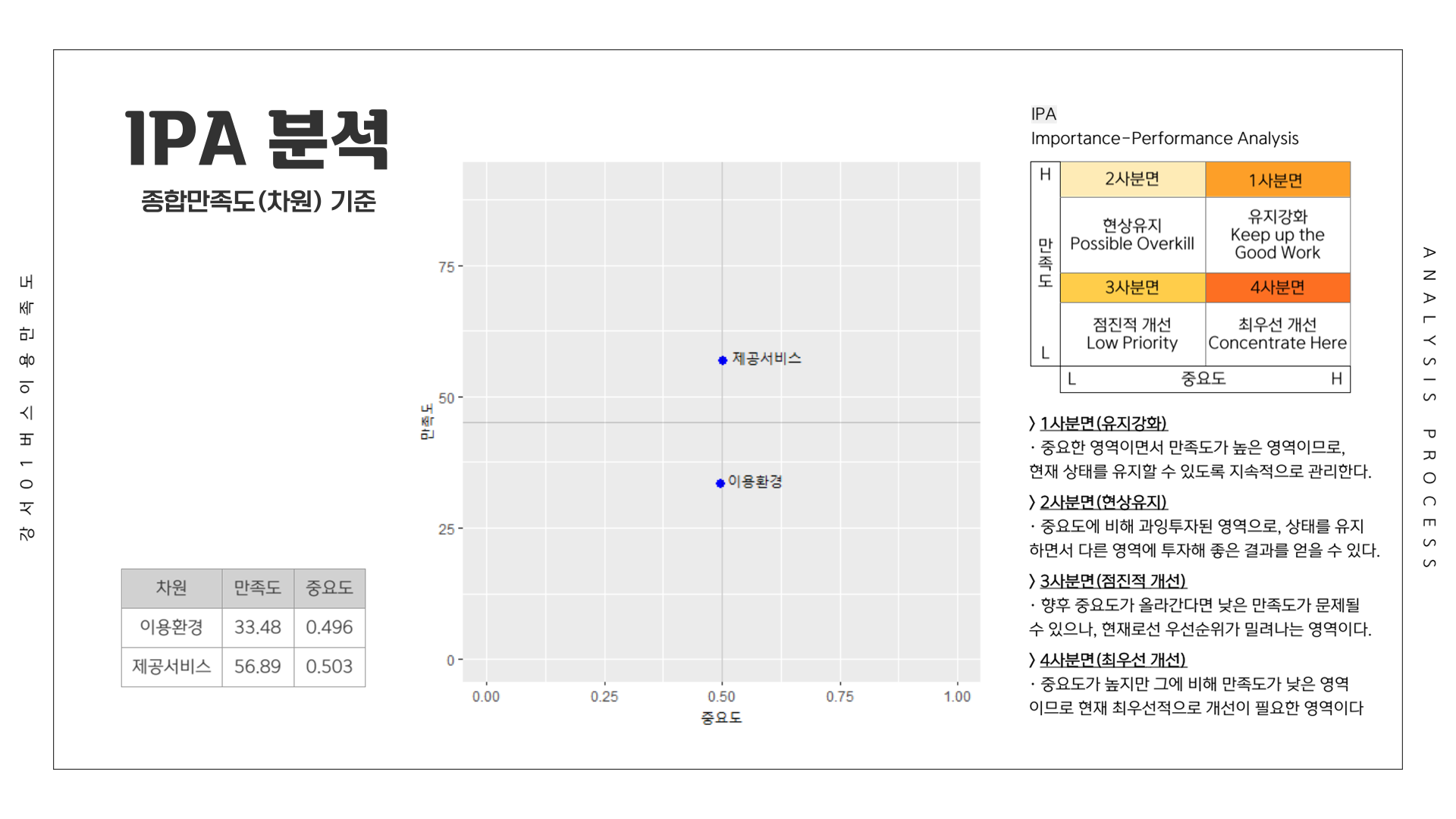
# IPA 중요도 계산
# 종합만족도
ipa_1 <- csi_total_tb1 %>%
get_summary_stats(이용환경, 제공서비스,
show = c("mean")) %>%
select(variable, mean) %>%
filter(!(variable == "종합만족도")) %>%
rename(항목 = variable, 만족도 = mean)
# 상관계수 이용
ipa_2 <- csi_total_tb1 %>%
cor_test(var1 = 종합만족도,
method = "pearson") %>%
select(var2, cor) %>%
mutate(wgt = cor/sum(cor)) %>%
select(wgt) %>%
rename(중요도 = wgt)
ipa_tb1 <- cbind(ipa_1, ipa_2)
ipa_tb1
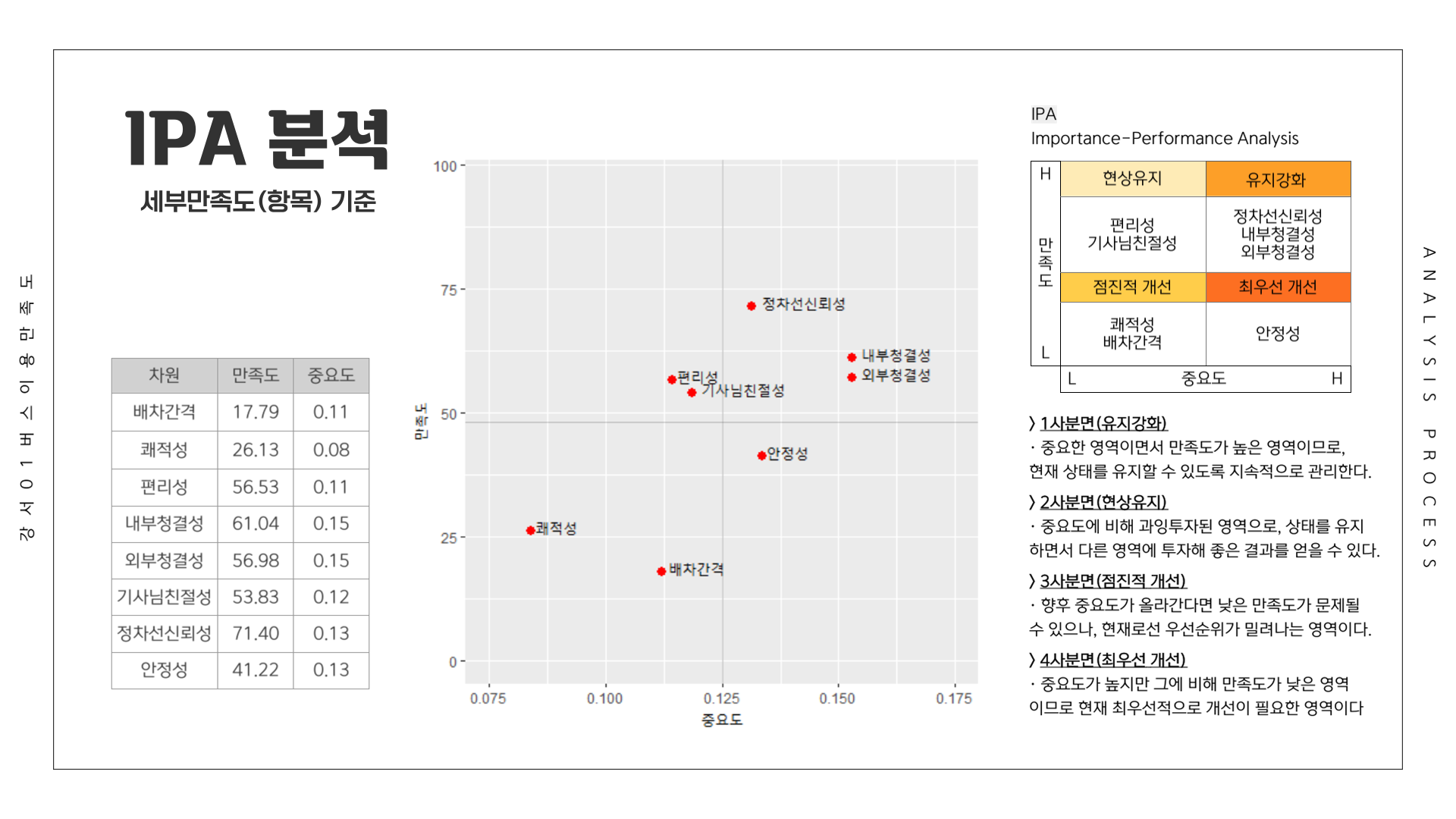
# 세부만족도
ipa_3 <- csi_total_tb2 %>%
get_summary_stats(배차간격, 쾌적성, 편리성,
내부청결성, 외부청결성, 기사님친절성, 정차선신뢰성, 안정성,
show = c("mean")) %>%
select(variable, mean) %>%
filter(!(variable == "세부만족도")) %>%
rename(항목 = variable, 만족도 = mean)
# 상관계수 이용
ipa_4 <- csi_total_tb2 %>%
cor_test(var1 = 세부만족도,
method = "pearson") %>%
select(var2, cor) %>%
mutate(wgt = cor/sum(cor)) %>%
select(wgt) %>%
rename(중요도 = wgt)
ipa_tb2 <- cbind(ipa_3, ipa_4)
ipa_tb2
# ipa_tb <- rbind(ipa_tb1, ipa_tb2)
ipa_tb1 %>%
write_excel_csv("3-1. IPA 분석 종합만족도.csv", col_names = T)
ipa_tb2 %>%
write_excel_csv("3-2. IPA 분석 세부만족도.csv", col_names = T) cor_text: 변수들 간의 상관계수와 유의성을 계산 # var1 인자를 통해 기준 변수를 지정할 수 있으며, 전반적만족도를 기준 변수로 설정합니다.
select: 데이터셋에서 필요한 열(columns)을 선택하는 함수입니다.
mutate: 데이터셋에 새로운 열(columns)을 추가하거나 기존 열을 수정하는 함수입니다.
tibble 형태로 변환된 데이터셋 csi_100_tb에서 cor_test() 함수를 이용하여 변수들 간의 상관관계를 계산하고, select() 함수와 mutate() 함수를 이용하여 필요한 변수와 가중치 값을 계산
method 인자를 통해 상관계수 계산 방법을 지정할 수 있으며, pearson 방법을 사용
mutate(종합만족도 = 전공교육 * 0.237 + 교양교육 * 0.247) 가중치 부여
IPA 그래프
# IPA 그래프
ipa_tb1 %>%
ggplot(mapping = aes(x = 중요도,
y = 만족도)) +
geom_point(shape = 20,
size = 4,
colour = "blue",
show.legend = FALSE) +
coord_cartesian(xlim = c(0.5 - 0.5, 0.5 + 0.5), # 중요도 평균 0.5
ylim = c(45.1875 - 45, 45.1875 + 45)) + # 만족도 평균 45.1875
geom_text(mapping = aes(label = 항목,
size = 0,
vjust = 0,
hjust = -0.12),
show.legend = FALSE) +
geom_vline(xintercept = 0.5,
size = 0.5,
alpha = 0.2) +
geom_hline(yintercept = 45.1875,
size = 0.5,
alpha = 0.2)
ipa_tb2 %>%
ggplot(mapping = aes(x = 중요도,
y = 만족도)) +
geom_point(shape = 20,
size = 4,
colour = "red",
show.legend = FALSE) +
coord_cartesian(xlim = c(0.125 - 0.05, 0.125 + 0.05), # 중요도 평균 0.125
ylim = c(48.11375 - 48, 48.11375 + 48)) + # 만족도 평균 48.11375
geom_text(mapping = aes(label = 항목,
size = 0,
vjust = 0,
hjust = -0.12),
show.legend = FALSE) +
geom_vline(xintercept = 0.125,
size = 0.5,
alpha = 0.2) +
geom_hline(yintercept = 48.11375,
size = 0.5,
alpha = 0.2)
프로젝트 요약
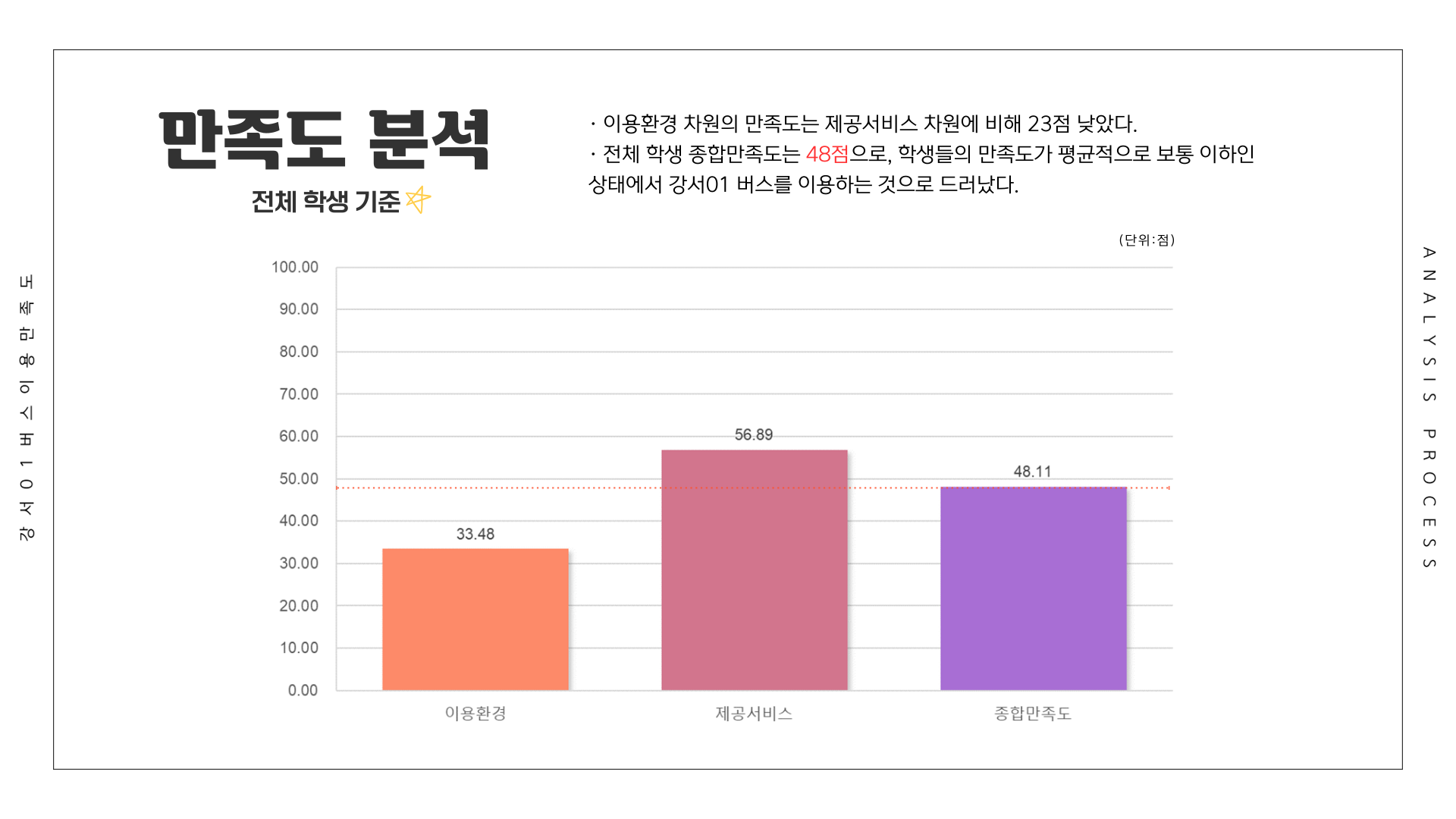
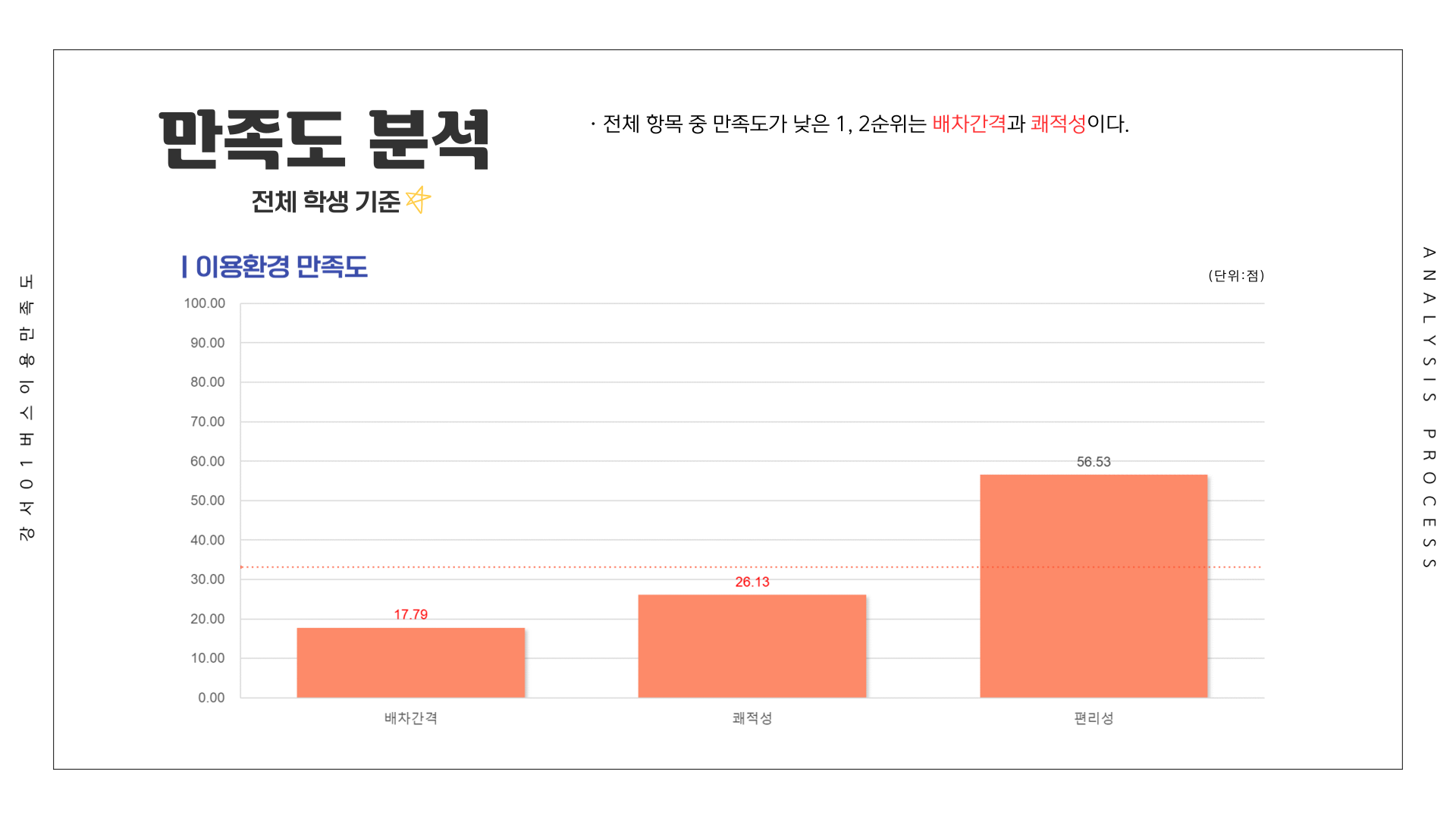
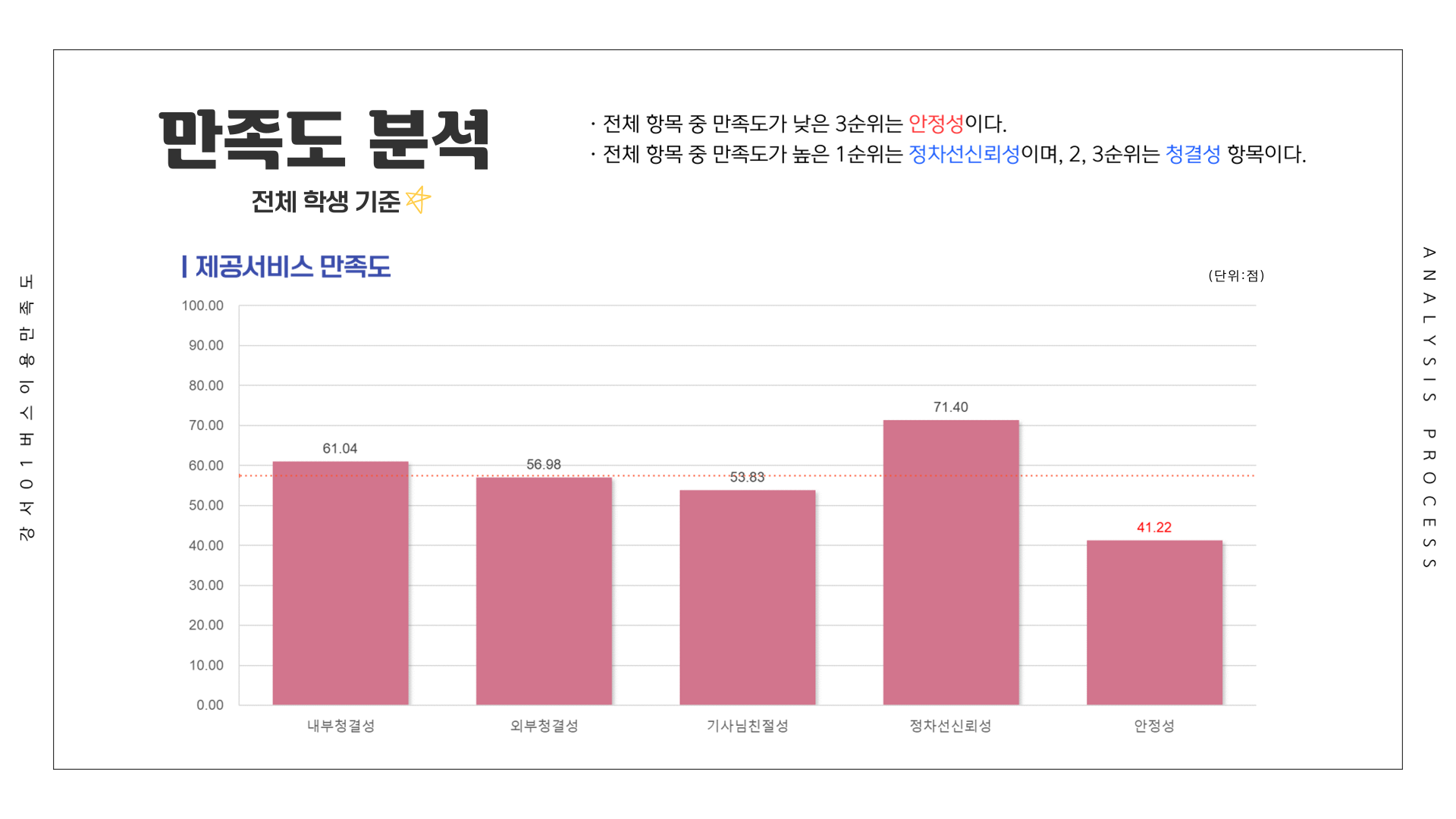
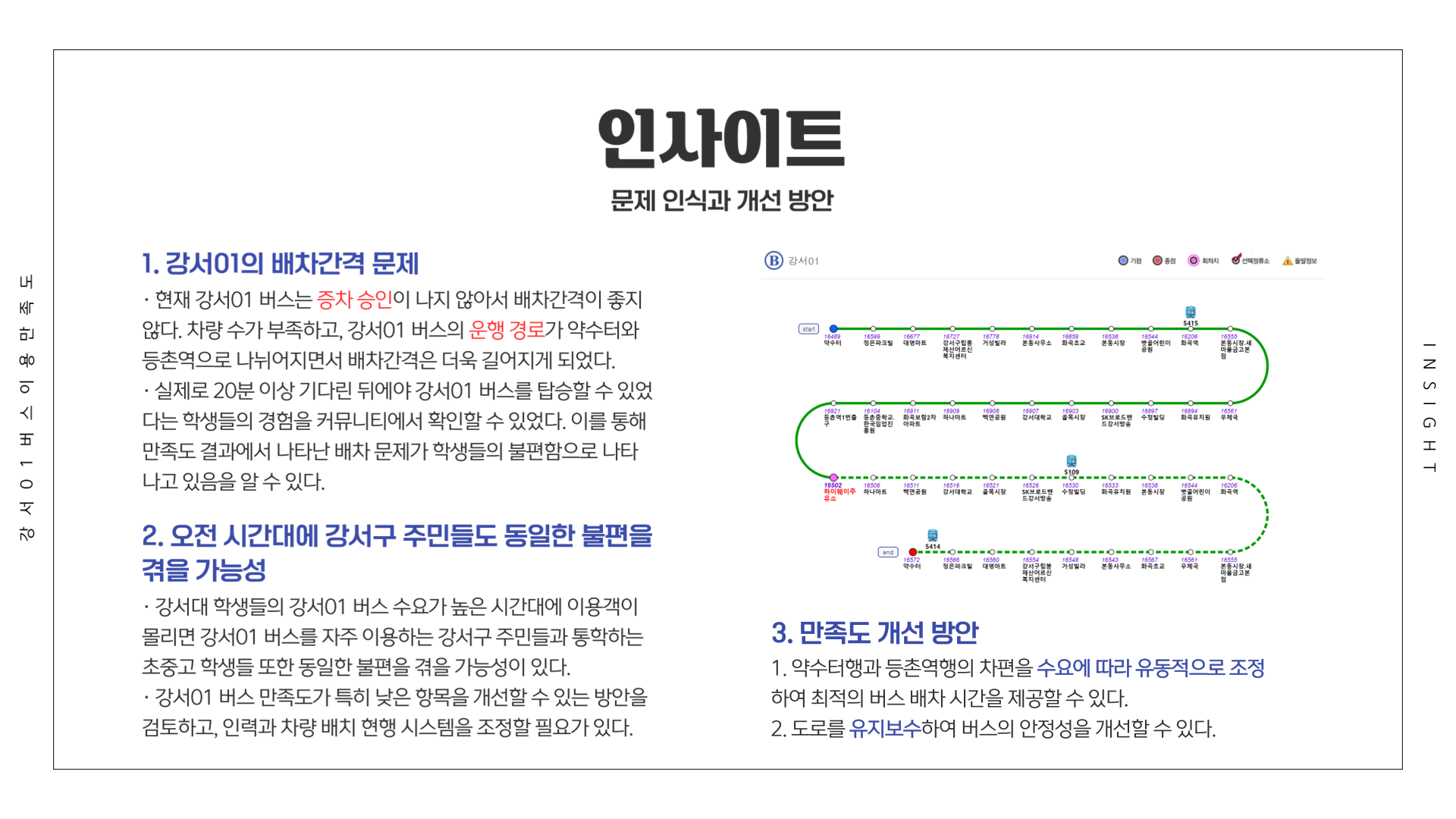
전체 응답자를 기준으로 가장 만족도가 낮았던 항목은 1위 배차간격(17.79점), 2위 쾌적성(26.13점), 3위 안정성(41.22점)이었습니다. 배차간격의 낮은 만족도를 확인하였고, 수요 등의 결과를 바탕으로 민원을 작성하였습니다.
프로젝트가 끝난 뒤에 강서01 버스 이용 만족도 요약과 분석 결과를 토대로 지역에 민원 상담을 받은 과정과 결과를 함께 공개했습니다.
5월 5일에 상담 민원을 등록하였고, 5월 11일에 상담 답변을 받게 되었습니다.

강서구 교통행정과 답변은 다음과 같습니다.
1. 코로나 이후에 승객이 감소했고, 요금이 900원으로 동결되어 업체가 경영난을 겪고 있다.
2. 구인난으로 인해 버스 기사가 적어 정상적인 운영이 어렵다.
3. 버스 업체의 운수종사자가 충당되면 배차간격을 단축하여 운영하겠다.
저는 강서01 버스경로가 약수터행, 등촌역행으로 나뉘어져서 배차간격이 길어지니까 동일하게 운영하지 말고, 만족도는 더 낮고 수요는 더 높은 오전시간에 등촌역행을 늘리는 등의 개선을 해달라는 요청을 드렸습니다.
하지만 버스 노선을 수정하면 그동안 이용하고 있던 다른 지역의 이용객의 불편이 예상되어 노선 수정은 어렵다는 답변을 받았습니다.
프로젝트 소감
이러한 불편을 인지했으니 앞으로 개선이 될 수도 있겠지만, 기약 없는 답변을 받아서 아쉬웠습니다.
프로젝트를 시작했던 목적은 만족도 분석 및 연구였습니다. 하지만 많은 학우와 주민들이 이러한 문제에 불편을 느끼고 있을 것을 알게 된 뒤로 정확하고 근거 있는 분석을 통해 주변 학우들의 불편을 해소하기 위해 문제를 해결하는 것을 목표로 하게 되었습니다.
이번 프로젝트는 분석을 통해 도출한 결과를 실제 근거 자료로 활용해 사용할 수 있었던 경험이었습니다. 비록 근본적인 문제가 해결되지 않아서 아쉬움도 있지만 학우들을 위해서 의미 있었던 시도였다고 생각합니다. 또한, 앞으로도 사회 문제의 개선을 위해서 내 능력을 사용해야겠다는 생각이 들었습니다.