















프로젝트 개요
-
구현 목표
Selenium 기술로 시편을 스크래핑하고, 텍스트 마이닝을 진행한다. 이를 통해 데이터 수집 및 분석 기법을 익히고, 다방면의 분석을 통해 연구 주제에 대해 이해도를 높일 수 있도록 한다.
-
활동 내용
- 웹 스크래핑: Selenium을 활용하여 Word Project 사이트에서 데이터 스크래핑
- 데이터 전처리: 스크래핑한 데이터에 대해 문서 전처리, 형태소 분석, 명사, 동사, 형용사 추출
- 단어 빈도 분석: 단어 빈도 그래프 및 워드 클라우드를 통해 시편에서 빈도가 높은 단어 도출
- 토픽 분석: 토픽 모델링을 통해 여러 토픽으로 분류하고, 토픽 간의 관계를 분석
- 감성 분석: 긍정 및 부정 단어를 파악하여 시편의 감성적인 내용을 이해
- Category
- Period
- GitHub
| 텍스트 마이닝 | |
| 2023.05.17.~2023.06.21. | |
| https://github.com/Isaac-Seungwon/text-mining-analysis-of-bible-psalms.git |
library 설정
# === library 설정 === #
# 크롤링 (스크래핑)
library(rvest)
library(readr)
library(stringr)
library(dplyr)
library(ggplot2)
# 형태소 분석
useNIADic() # 단어사전
library(KoNLP)
library(multilinguer)
library(tidyverse)
library(tidytext)
# 동시발생빈도
library(igraph)
library(widyr)
library(tidygraph)
library(ggraph)
library(viridis)
# 워드클라우드
library(wordcloud)
library(wordcloud2)
library(ggwordcloud)
library(showtext)
# 토픽분석
library(quanteda)
library(tm)
library(stm)
library(furrr)
library(ggthemes) 크롤링 (스크래핑)
rvest: 웹 페이지 스크래핑을 위한 패키지입니다. HTML 페이지에서 데이터를 추출하고, 원하는 정보를 가져오는 데 사용합니다.
readr: 데이터 파일 읽기 및 로드를 위한 패키지이며, tidyverse 패키지 중 하나입니다. csv, tsv, fwf 등의 격자형의 데이터 파일을 쉽고 편하게 읽기 위해 만들어졌습니다.
stringr: 문자열 처리 및 조작을 위한 패키지입니다. 문자열을 쉽게 처리할 수 있도록 설계 함수 세트를 제공하므로 텍스트 데이터에서 패턴을 찾고 조작하는 데 사용합니다.
dplyr: 데이터 처리에 특화된 패키지입니다. 데이터프레임에서 간편하게 데이터를 조작할 수 있습니다.
ggplot2: 데이터 시각화를 위한 패키지입니다. 다양한 그래프와 차트를 생성하고 데이터를 시각적으로 표현하는 데 사용합니다.
형태소 분석
useNIADic: 한국어 단어사전 사용을 위한 함수입니다. 한국어 텍스트에서 단어를 추출하거나 사전을 참조하는 데 사용합니다.
KoNLP: 한국어 형태소 분석을 위한 패키지입니다. 한국어 텍스트를 형태소 단위로 분석하고 다양한 텍스트 마이닝 작업에 사용합니다.
multilinguer: 다국어 처리 및 다양한 언어 지원을 위한 패키지입니다. 여러 언어로 작성된 텍스트 데이터를 다룰 때 유용하게 사용합니다.
tidyverse: 데이터 가공 및 시각화를 위한 종합 패키지입니다. dplyr, ggplot2 등을 포함하며 효율적인 데이터 처리와 시각화를 지원합니다.
tidytext: 텍스트 데이터를 다루기 위한 tidyverse 스타일의 패키지입니다. 텍스트 분석 및 텍스트 마이닝 작업을 수행할 때 유용하게 사용합니다.
동시발생빈도
igraph: 그래프 이론을 다루기 위한 패키지입니다. 복잡한 네트워크 구조를 분석하고 시각화하는 데 사용합니다.
widyr: 데이터 프레임에서 동시발생 빈도를 계산하기 위한 패키지입니다. tidyverse 스타일의 데이터 가공을 지원합니다.
tidygraph: tidyverse와 함께 사용되는 그래프 패키지입니다. 데이터 프레임을 이용한 그래프 분석이 가능합니다.
ggraph: 그래프 시각화를 위한 패키지입니다. tidygraph와 함께 사용하여 그래프를 예쁘게 그릴 수 있습니다.
viridis: 시각화에서 사용할 수 있는 색상 팔레트를 제공하는 패키지입니다. 그래프나 워드클라우드 등에서 색상을 효과적으로 사용할 수 있습니다.
워드클라우드
wordcloud: 워드클라우드 생성을 위한 패키지입니다. 텍스트 데이터에서 빈도가 높은 단어를 시각적으로 표현합니다.
wordcloud2: 인터랙티브 워드클라우드를 생성하기 위한 패키지입니다. 웹 기반에서 상호작용 가능한 워드클라우드를 만들 수 있습니다.
ggwordcloud: ggplot2를 이용한 워드클라우드 생성을 지원하는 패키지입니다. ggplot2의 기능을 활용하여 다양한 스타일의 워드클라우드를 만들 수 있습니다.
showtext: 폰트 설정을 관리하는 패키지입니다. 워드클라우드나 그래프의 폰트의 설정에 사용합니다.
토픽 분석
quanteda: 텍스트 마이닝을 위한 종합적인 패키지입니다. 다양한 텍스트 분석 작업을 지원합니다.
tm: 텍스트 마이닝을 위한 기본 패키지입니다. 텍스트 전처리 및 기본적인 분석을 수행할 수 있습니다.
stm: 구조적 토픽 모델링을 위한 패키지입니다. 텍스트 데이터의 토픽을 추출하고 관계를 분석하는 데 사용합니다.
furrr: 병렬 처리를 지원하는 패키지입니다. 대용량 텍스트 데이터를 효율적으로 처리할 때 사용합니다.
ggthemes: ggplot2 테마 설정을 지원하는 패키지입니다. 그래프의 스타일, 테마를 설정할 수 있습니다.
시편 스크래핑
웹 크롤링 & 웹 스크래핑
웹 크롤링과 웹 스크래핑은 모두 데이터를 웹 상의 수집한다는 점은 같지만, 스크래핑은 모든 페이지에 대한 데이터를 추출하고, 스크래핑은 특정 웹 사이트나 페이지에서 필요한 데이터를 추출한다는 점에서 차이가 있습니다.
엄밀히 하면, 웹 크롤링과 웹 스크래핑은 이러한 점에서 목적과 프로세스의 차이가 있습니다. 그러나 실제로는 두 용어가 종종 혼용되곤 합니다.
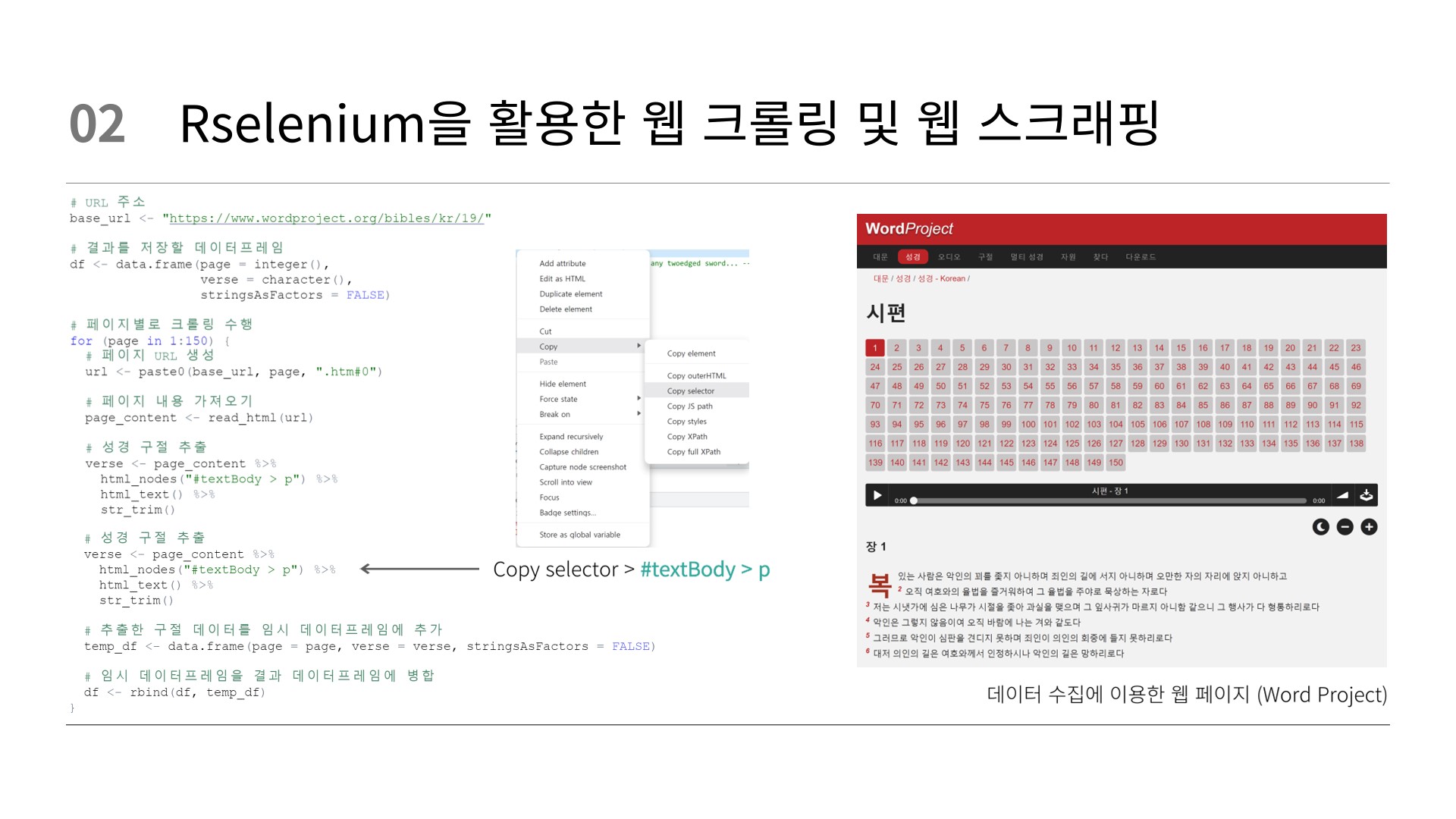
# === 성경 스크래핑 === #
## 시편
# 스크래핑할 URL 주소
base_url <- "https://www.wordproject.org/bibles/kr/19/"
# 스크래핑할 페이지 범위
start_page <- 1
end_page <- 150
# 결과를 저장할 데이터프레임
df <- data.frame(page = integer(),
verse = character(),
stringsAsFactors = FALSE)
# 페이지별로 스크래핑 수행
for (page in start_page:end_page) {
# 페이지 URL 생성
url <- paste0(base_url, page, ".htm#0")
# 페이지 내용 가져오기
page_content <- read_html(url)
# 성경 구절 추출
verse <- page_content %>%
html_nodes("#textBody > p") %>%
html_text() %>%
str_trim()
# 추출한 구절 데이터를 임시 데이터프레임에 추가
temp_df <- data.frame(page = page, verse = verse, stringsAsFactors = FALSE)
# 임시 데이터프레임을 결과 데이터프레임에 병합
df <- rbind(df, temp_df)
}
# 결과를 CSV 파일로 출력
output_file <- "Psalter_verses.csv"
write_excel_csv(df, path = output_file)
# 스크래핑 결과 출력
unique_pages <- unique(df$page)
for (page in unique_pages) {
cat(paste0("=== Page ", page, " ===\n"))
cat(df[df$page == page, "verse"], "\n\n")
} cat() 함수: 출력 결과를 콘솔에 텍스트 형식으로 표시하는 데 사용되는 R의 내장 함수입니다.
cat() 함수는 스크래핑 결과를 페이지별로 출력하는 역할을 합니다.
paste() 함수: 함수는 여러 개의 문자열을 하나로 결합할 때 사용되는 함수입니다.
주어진 문자열을 연결하여 새로운 문자열을 생성합니다. 주로 콘솔 출력이나 파일에 내용을 작성할 때 사용합니다.
"=== Page X ===" 형식의 페이지 헤더를 생성한 후, 이를 cat() 함수를 통해 콘솔에 출력합니다. 그 다음, df[df$page == page, "verse"]를 사용하여 해당 페이지에 대한 구절 데이터를 선택하고, 다시 cat() 함수를 사용하여 구절 데이터를 콘솔에 출력합니다.
창세기 스크래핑
## 창세기
# 스크래핑할 URL 주소
base_url <- "https://www.wordproject.org/bibles/kr/01/"
# 스크래핑할 페이지 범위
start_page <- 1
end_page <- 50
# 결과를 저장할 데이터프레임
df <- data.frame(page = integer(),
verse = character(),
stringsAsFactors = FALSE)
# 페이지별로 스크래핑 수행
for (page in start_page:end_page) {
# 페이지 URL 생성
url <- paste0(base_url, page, ".htm#0")
# 페이지 내용 가져오기
page_content <- read_html(url)
# 성경 구절 추출
verse <- page_content %>%
html_nodes("#textBody > p") %>%
html_text() %>%
str_trim()
# 추출한 구절 데이터를 임시 데이터프레임에 추가
temp_df <- data.frame(page = page, verse = verse, stringsAsFactors = FALSE)
# 임시 데이터프레임을 결과 데이터프레임에 병합
df <- rbind(df, temp_df)
}
# 결과를 CSV 파일로 출력
output_file <- "Genesis_verses.csv"
write_excel_csv(df, path = output_file)
# 스크래핑 결과 출력
unique_pages <- unique(df$page)
for (page in unique_pages) {
cat(paste0("=== Page ", page, " ===\n"))
cat(df[df$page == page, "verse"], "\n\n")
}출애굽기 스크래핑
## 출애굽기
# 스크래핑할 URL 주소
base_url <- "https://www.wordproject.org/bibles/kr/02/"
# 스크래핑할 페이지 범위
start_page <- 1
end_page <- 40
# 결과를 저장할 데이터프레임
df <- data.frame(page = integer(),
verse = character(),
stringsAsFactors = FALSE)
# 페이지별로 스크래핑 수행
for (page in start_page:end_page) {
# 페이지 URL 생성
url <- paste0(base_url, page, ".htm#0")
# 페이지 내용 가져오기
page_content <- read_html(url)
# 성경 구절 추출
verse <- page_content %>%
html_nodes("#textBody > p") %>%
html_text() %>%
str_trim()
# 추출한 구절 데이터를 임시 데이터프레임에 추가
temp_df <- data.frame(page = page, verse = verse, stringsAsFactors = FALSE)
# 임시 데이터프레임을 결과 데이터프레임에 병합
df <- rbind(df, temp_df)
}
# 결과를 CSV 파일로 출력
output_file <- "Exodus_verses.csv"
write_excel_csv(df, path = output_file)
# 스크래핑 결과 출력
unique_pages <- unique(df$page)
for (page in unique_pages) {
cat(paste0("=== Page ", page, " ===\n"))
cat(df[df$page == page, "verse"], "\n\n")
}레위기 스크래핑
## 레위기
# 스크래핑할 URL 주소
base_url <- "https://www.wordproject.org/bibles/kr/03/"
# 스크래핑할 페이지 범위
start_page <- 1
end_page <- 27
# 결과를 저장할 데이터프레임
df <- data.frame(page = integer(),
verse = character(),
stringsAsFactors = FALSE)
# 페이지별로 스크래핑 수행
for (page in start_page:end_page) {
# 페이지 URL 생성
url <- paste0(base_url, page, ".htm#0")
# 페이지 내용 가져오기
page_content <- read_html(url)
# 성경 구절 추출
verse <- page_content %>%
html_nodes("#textBody > p") %>%
html_text() %>%
str_trim()
# 추출한 구절 데이터를 임시 데이터프레임에 추가
temp_df <- data.frame(page = page, verse = verse, stringsAsFactors = FALSE)
# 임시 데이터프레임을 결과 데이터프레임에 병합
df <- rbind(df, temp_df)
}
# 결과를 CSV 파일로 출력
output_file <- "Leviticus_verses.csv"
write_excel_csv(df, path = output_file)
# 스크래핑 결과 출력
unique_pages <- unique(df$page)
for (page in unique_pages) {
cat(paste0("=== Page ", page, " ===\n"))
cat(df[df$page == page, "verse"], "\n\n")
}민수기 스크래핑
## 민수기
# 스크래핑할 URL 주소
base_url <- "https://www.wordproject.org/bibles/kr/04/"
# 스크래핑할 페이지 범위
start_page <- 1
end_page <- 36
# 결과를 저장할 데이터프레임
df <- data.frame(page = integer(),
verse = character(),
stringsAsFactors = FALSE)
# 페이지별로 스크래핑 수행
for (page in start_page:end_page) {
# 페이지 URL 생성
url <- paste0(base_url, page, ".htm#0")
# 페이지 내용 가져오기
page_content <- read_html(url)
# 성경 구절 추출
verse <- page_content %>%
html_nodes("#textBody > p") %>%
html_text() %>%
str_trim()
# 추출한 구절 데이터를 임시 데이터프레임에 추가
temp_df <- data.frame(page = page, verse = verse, stringsAsFactors = FALSE)
# 임시 데이터프레임을 결과 데이터프레임에 병합
df <- rbind(df, temp_df)
}
# 결과를 CSV 파일로 출력
output_file <- "Numbers_verses.csv"
write_excel_csv(df, path = output_file)
# 스크래핑 결과 출력
unique_pages <- unique(df$page)
for (page in unique_pages) {
cat(paste0("=== Page ", page, " ===\n"))
cat(df[df$page == page, "verse"], "\n\n")
}신명기 스크래핑
## 신명기
# 스크래핑할 URL 주소
base_url <- "https://www.wordproject.org/bibles/kr/05/"
# 스크래핑할 페이지 범위
start_page <- 1
end_page <- 34
# 결과를 저장할 데이터프레임
df <- data.frame(page = integer(),
verse = character(),
stringsAsFactors = FALSE)
# 페이지별로 스크래핑 수행
for (page in start_page:end_page) {
# 페이지 URL 생성
url <- paste0(base_url, page, ".htm#0")
# 페이지 내용 가져오기
page_content <- read_html(url)
# 성경 구절 추출
verse <- page_content %>%
html_nodes("#textBody > p") %>%
html_text() %>%
str_trim()
# 추출한 구절 데이터를 임시 데이터프레임에 추가
temp_df <- data.frame(page = page, verse = verse, stringsAsFactors = FALSE)
# 임시 데이터프레임을 결과 데이터프레임에 병합
df <- rbind(df, temp_df)
}
# 결과를 CSV 파일로 출력
output_file <- "Deuteronomy_verses.csv"
write_excel_csv(df, path = output_file)
# 스크래핑 결과 출력
unique_pages <- unique(df$page)
for (page in unique_pages) {
cat(paste0("=== Page ", page, " ===\n"))
cat(df[df$page == page, "verse"], "\n\n")
} 데이터 가져오기
# === 형태소 분석 === #
# 데이터 가져오기 (시편)
tm_tb <- read_csv('Psalter_verses.csv',
col_names = TRUE,
na = ".")
tm_tb
# 데이터 가져오기 (창세기)
tm_tb_genesis <- read_csv('Genesis_verses.csv',
col_names = TRUE,
na = ".")
tm_tb_genesis
# 데이터 가져오기 (출애굽기)
tm_tb_exodus <- read_csv('Exodus_verses.csv',
col_names = TRUE,
na = ".")
tm_tb_exodus
# 데이터 가져오기 (레위기)
tm_tb_leviticus <- read_csv('Leviticus_verses.csv',
col_names = TRUE,
na = ".")
tm_tb_leviticus
# 데이터 가져오기 (민수기)
tm_tb_numbers <- read_csv('Numbers_verses.csv',
col_names = TRUE,
na = ".")
tm_tb_numbers
# 데이터 가져오기 (신명기)
tm_tb_deuteronomy <- read_csv('Deuteronomy_verses.csv',
col_names = TRUE,
na = ".")
tm_tb_deuteronomy
# BOOK # 페이지별 데이터 저장
psalter_book1 <- tm_tb[tm_tb$page >= 1 & tm_tb$page <= 41, ]
psalter_book2 <- tm_tb[tm_tb$page >= 42 & tm_tb$page <= 72, ]
psalter_book3 <- tm_tb[tm_tb$page >= 73 & tm_tb$page <= 89, ]
psalter_book4 <- tm_tb[tm_tb$page >= 90 & tm_tb$page <= 106, ]
psalter_book5 <- tm_tb[tm_tb$page >= 107 & tm_tb$page <= 150, ]
# BOOK # 저장된 데이터 확인
psalter_book1
psalter_book2
psalter_book3
psalter_book4
psalter_book5 문서 전처리
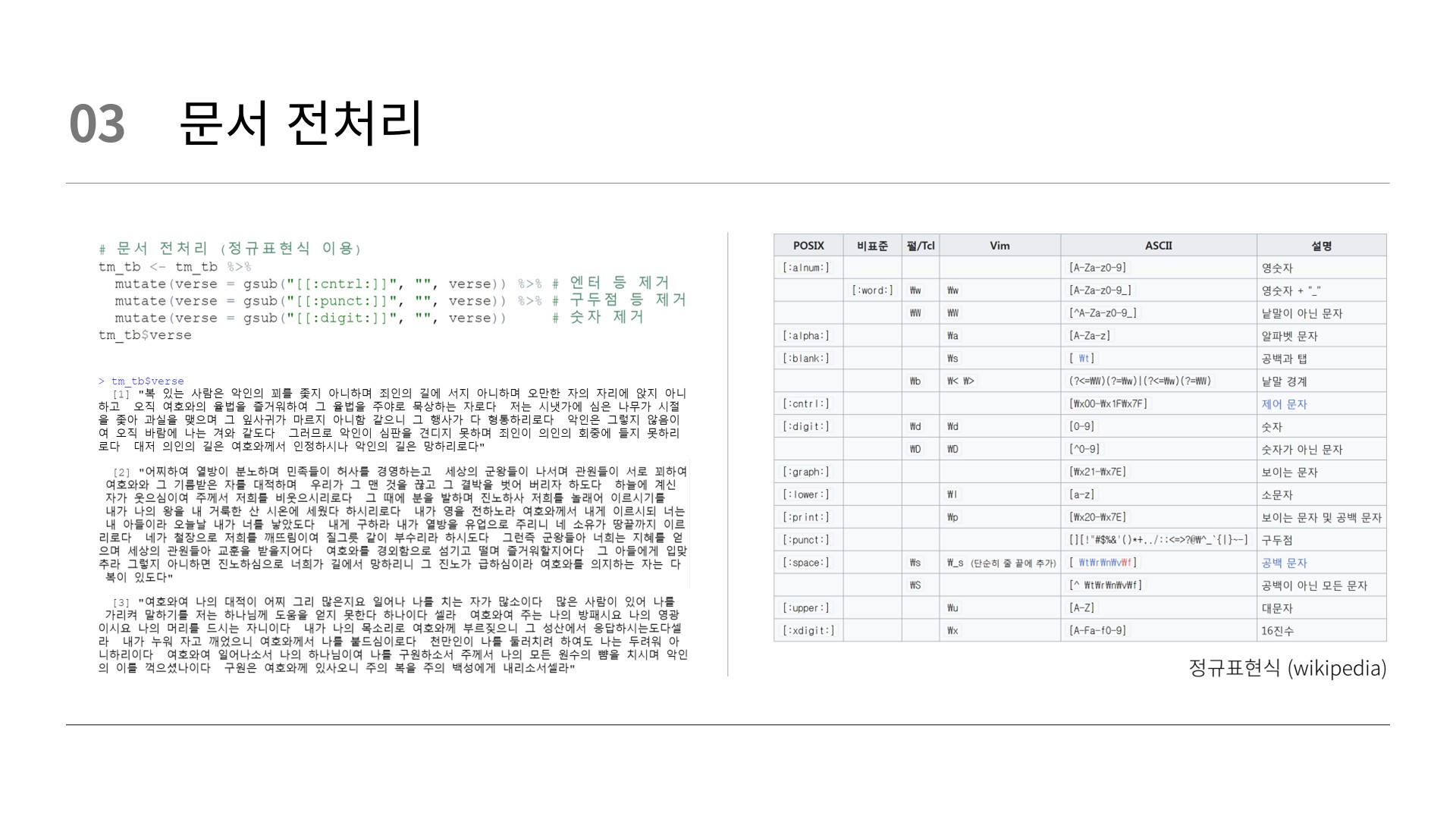
# 문서 전처리 (시편) (정규표현식 이용)
tm_tb <- tm_tb %>%
mutate(verse = gsub("[[:cntrl:]]", "", verse)) %>% # 엔터 등 제거
mutate(verse = gsub("[[:punct:]]", "", verse)) %>% # 구두점 등 제거
mutate(verse = gsub("[[:digit:]]", "", verse)) # 숫자 제거
tm_tb$verse
# 문서 전처리 (창세기)
tm_tb_genesis <- tm_tb_genesis %>%
mutate(verse = gsub("[[:cntrl:]]", "", verse)) %>% # 엔터 등 제거
mutate(verse = gsub("[[:punct:]]", "", verse)) %>% # 구두점 등 제거
mutate(verse = gsub("[[:digit:]]", "", verse)) # 숫자 제거
tm_tb_genesis$verse
# 문서 전처리 (출애굽기)
tm_tb_exodus <- tm_tb_exodus %>%
mutate(verse = gsub("[[:cntrl:]]", "", verse)) %>% # 엔터 등 제거
mutate(verse = gsub("[[:punct:]]", "", verse)) %>% # 구두점 등 제거
mutate(verse = gsub("[[:digit:]]", "", verse)) # 숫자 제거
tm_tb_exodus$verse
# 문서 전처리 (레위기)
tm_tb_leviticus <- tm_tb_leviticus %>%
mutate(verse = gsub("[[:cntrl:]]", "", verse)) %>% # 엔터 등 제거
mutate(verse = gsub("[[:punct:]]", "", verse)) %>% # 구두점 등 제거
mutate(verse = gsub("[[:digit:]]", "", verse)) # 숫자 제거
tm_tb_leviticus$verse
# 문서 전처리 (민수기)
tm_tb_numbers <- tm_tb_numbers %>%
mutate(verse = gsub("[[:cntrl:]]", "", verse)) %>% # 엔터 등 제거
mutate(verse = gsub("[[:punct:]]", "", verse)) %>% # 구두점 등 제거
mutate(verse = gsub("[[:digit:]]", "", verse)) # 숫자 제거
tm_tb_numbers$verse
# 문서 전처리 (신명기)
tm_tb_deuteronomy <- tm_tb_deuteronomy %>%
mutate(verse = gsub("[[:cntrl:]]", "", verse)) %>% # 엔터 등 제거
mutate(verse = gsub("[[:punct:]]", "", verse)) %>% # 구두점 등 제거
mutate(verse = gsub("[[:digit:]]", "", verse)) # 숫자 제거
tm_tb_deuteronomy$verse
# BOOK # 문서 전처리 (정규표현식 이용)
psalter_book1 <- psalter_book1 %>%
mutate(verse = gsub("[[:cntrl:]]", "", verse)) %>% # 엔터 등 제거
mutate(verse = gsub("[[:punct:]]", "", verse)) %>% # 구두점 등 제거
mutate(verse = gsub("[[:digit:]]", "", verse)) # 숫자 제거
psalter_book1$verse
psalter_book2 <- psalter_book2 %>%
mutate(verse = gsub("[[:cntrl:]]", "", verse)) %>% # 엔터 등 제거
mutate(verse = gsub("[[:punct:]]", "", verse)) %>% # 구두점 등 제거
mutate(verse = gsub("[[:digit:]]", "", verse)) # 숫자 제거
psalter_book2$verse
psalter_book3 <- psalter_book3 %>%
mutate(verse = gsub("[[:cntrl:]]", "", verse)) %>% # 엔터 등 제거
mutate(verse = gsub("[[:punct:]]", "", verse)) %>% # 구두점 등 제거
mutate(verse = gsub("[[:digit:]]", "", verse)) # 숫자 제거
psalter_book3$verse
psalter_book4 <- psalter_book4 %>%
mutate(verse = gsub("[[:cntrl:]]", "", verse)) %>% # 엔터 등 제거
mutate(verse = gsub("[[:punct:]]", "", verse)) %>% # 구두점 등 제거
mutate(verse = gsub("[[:digit:]]", "", verse)) # 숫자 제거
psalter_book4$verse
psalter_book5 <- psalter_book5 %>%
mutate(verse = gsub("[[:cntrl:]]", "", verse)) %>% # 엔터 등 제거
mutate(verse = gsub("[[:punct:]]", "", verse)) %>% # 구두점 등 제거
mutate(verse = gsub("[[:digit:]]", "", verse)) # 숫자 제거
psalter_book5$verse 형태소 분석
# 형태소 분석
word_tb <- tm_tb %>%
select(page, verse) %>%
unnest_tokens(input = verse,
output = morp,
token = SimplePos09) %>% # 한글 형태소로 분리
mutate(word = str_remove(morp, "/.*$")) %>% # 형태소 정보 제거
filter(str_length(word) >= 2)
word_tb %>%
print(n = 20)
# 형태소 분석 (창세기)
word_tb_genesis <- tm_tb_genesis %>%
select(page, verse) %>%
#(!(page == 1)) %>%
unnest_tokens(input = verse,
output = morp,
token = SimplePos09) %>% # 한글 형태소로 분리
mutate(word = str_remove(morp, "/.*$")) %>% # 형태소 정보 제거
filter(str_length(word) >= 2)
word_tb_genesis
# 형태소 분석 (출애굽기)
word_tb_exodus <- tm_tb_exodus %>%
select(page, verse) %>%
#(!(page == 1)) %>%
unnest_tokens(input = verse,
output = morp,
token = SimplePos09) %>% # 한글 형태소로 분리
mutate(word = str_remove(morp, "/.*$")) %>% # 형태소 정보 제거
filter(str_length(word) >= 2)
word_tb_exodus
# 형태소 분석 (레위기)
word_tb_leviticus <- tm_tb_leviticus %>%
select(page, verse) %>%
#(!(page == 1)) %>%
unnest_tokens(input = verse,
output = morp,
token = SimplePos09) %>% # 한글 형태소로 분리
mutate(word = str_remove(morp, "/.*$")) %>% # 형태소 정보 제거
filter(str_length(word) >= 2)
word_tb_leviticus
# 형태소 분석 (민수기)
word_tb_numbers <- tm_tb_numbers %>%
select(page, verse) %>%
#(!(page == 1)) %>%
unnest_tokens(input = verse,
output = morp,
token = SimplePos09) %>% # 한글 형태소로 분리
mutate(word = str_remove(morp, "/.*$")) %>% # 형태소 정보 제거
filter(str_length(word) >= 2)
word_tb_numbers
# 형태소 분석 (신명기)
word_tb_deuteronomy <- tm_tb_deuteronomy %>%
select(page, verse) %>%
#(!(page == 1)) %>%
unnest_tokens(input = verse,
output = morp,
token = SimplePos09) %>% # 한글 형태소로 분리
mutate(word = str_remove(morp, "/.*$")) %>% # 형태소 정보 제거
filter(str_length(word) >= 2)
word_tb_deuteronomy
# BOOK # 형태소 분석
word_tb_book1 <- psalter_book1 %>%
select(page, verse) %>%
#(!(page == 1)) %>%
unnest_tokens(input = verse,
output = morp,
token = SimplePos09) %>% # 한글 형태소로 분리
mutate(word = str_remove(morp, "/.*$")) %>% # 형태소 정보 제거
filter(str_length(word) >= 2)
word_tb_book1
word_tb_book2 <- psalter_book2 %>%
select(page, verse) %>%
#(!(page == 1)) %>%
unnest_tokens(input = verse,
output = morp,
token = SimplePos09) %>% # 한글 형태소로 분리
mutate(word = str_remove(morp, "/.*$")) %>% # 형태소 정보 제거
filter(str_length(word) >= 2)
word_tb_book2
word_tb_book3 <- psalter_book3 %>%
select(page, verse) %>%
#(!(page == 1)) %>%
unnest_tokens(input = verse,
output = morp,
token = SimplePos09) %>% # 한글 형태소로 분리
mutate(word = str_remove(morp, "/.*$")) %>% # 형태소 정보 제거
filter(str_length(word) >= 2)
word_tb_book3
word_tb_book4 <- psalter_book4 %>%
select(page, verse) %>%
#(!(page == 1)) %>%
unnest_tokens(input = verse,
output = morp,
token = SimplePos09) %>% # 한글 형태소로 분리
mutate(word = str_remove(morp, "/.*$")) %>% # 형태소 정보 제거
filter(str_length(word) >= 2)
word_tb_book4
word_tb_book5 <- psalter_book5 %>%
select(page, verse) %>%
#(!(page == 1)) %>%
unnest_tokens(input = verse,
output = morp,
token = SimplePos09) %>% # 한글 형태소로 분리
mutate(word = str_remove(morp, "/.*$")) %>% # 형태소 정보 제거
filter(str_length(word) >= 2)
word_tb_book5 명사 추출
# 명사추출 (시편)
word_n_tb <- word_tb %>%
filter(str_detect(morp, "/n"))# 명사 추출
# 명사추출 (창세기)
word_n_tb_genesis <- word_tb_genesis %>%
filter(str_detect(morp, "/n"))# 명사 추출
# 명사추출 (출애굽기)
word_n_tb_exodus <- word_tb_exodus %>%
filter(str_detect(morp, "/n"))# 명사 추출
# 명사추출 (레위기)
word_n_tb_leviticus <- word_tb_leviticus %>%
filter(str_detect(morp, "/n"))# 명사 추출
# 명사추출 (민수기)
word_n_tb_numbers <- word_tb_numbers %>%
filter(str_detect(morp, "/n"))# 명사 추출
# 명사추출 (신명기)
word_n_tb_deuteronomy <- word_tb_deuteronomy %>%
filter(str_detect(morp, "/n"))# 명사 추출
word_n_tb %>%
print(n = 20)
word_n_tb_genesis %>%
print(n = 20)
word_n_tb_exodus %>%
print(n = 20)
word_n_tb_leviticus %>%
print(n = 20)
word_n_tb_numbers %>%
print(n = 20)
word_n_tb_deuteronomy %>%
print(n = 20)
# BOOK # 명사추출
word_n_tb_book1 <- word_tb_book1 %>%
filter(str_detect(morp, "/n"))
word_n_tb_book2 <- word_tb_book2 %>%
filter(str_detect(morp, "/n"))
word_n_tb_book3 <- word_tb_book3 %>%
filter(str_detect(morp, "/n"))
word_n_tb_book4 <- word_tb_book4 %>%
filter(str_detect(morp, "/n"))
word_n_tb_book5 <- word_tb_book5 %>%
filter(str_detect(morp, "/n"))
word_n_tb_book1 %>%
print(n = 20)
word_n_tb_book2 %>%
print(n = 20)
word_n_tb_book3 %>%
print(n = 20)
word_n_tb_book4 %>%
print(n = 20)
word_n_tb_book5 %>%
print(n = 20) 동사, 형용사 추출
# 동사, 형용사 추출 (시편)
word_p_tb <- word_tb %>%
filter(str_detect(morp, "/p")) %>% # 동사, 형용사 추출
mutate(word = str_replace(morp, "/.*$", "다")) # 형태소 정보 제거
# 동사, 형용사 추출 (창세기)
word_p_tb_genesis <- word_tb_genesis %>%
filter(str_detect(morp, "/p")) %>% # 동사, 형용사 추출
mutate(word = str_replace(morp, "/.*$", "다")) # 형태소 정보 제거
# 동사, 형용사 추출 (출애굽기)
word_p_tb_exodus <- word_tb_exodus %>%
filter(str_detect(morp, "/p")) %>% # 동사, 형용사 추출
mutate(word = str_replace(morp, "/.*$", "다")) # 형태소 정보 제거
# 동사, 형용사 추출 (레위기)
word_p_tb_leviticus <- word_tb_leviticus %>%
filter(str_detect(morp, "/p")) %>% # 동사, 형용사 추출
mutate(word = str_replace(morp, "/.*$", "다")) # 형태소 정보 제거
# 동사, 형용사 추출 (민수기)
word_p_tb_numbers <- word_tb_numbers %>%
filter(str_detect(morp, "/p")) %>% # 동사, 형용사 추출
mutate(word = str_replace(morp, "/.*$", "다")) # 형태소 정보 제거
# 동사, 형용사 추출 (신명기)
word_p_tb_deuteronomy <- word_tb_deuteronomy %>%
filter(str_detect(morp, "/p")) %>% # 동사, 형용사 추출
mutate(word = str_replace(morp, "/.*$", "다")) # 형태소 정보 제거
word_p_tb %>%
print(n = 20)
word_p_tb_genesis %>%
print(n = 20)
word_p_tb_exodus %>%
print(n = 20)
word_p_tb_leviticus %>%
print(n = 20)
word_p_tb_numbers %>%
print(n = 20)
word_p_tb_deuteronomy %>%
print(n = 20)
# BOOK # 동사, 형용사 추출
word_p_tb_book1 <- word_tb_book1 %>%
filter(str_detect(morp, "/p")) %>% # 동사, 형용사 추출
mutate(word = str_replace(morp, "/.*$", "다")) # 형태소 정보 제거
word_p_tb_book2 <- word_tb_book2 %>%
filter(str_detect(morp, "/p")) %>% # 동사, 형용사 추출
mutate(word = str_replace(morp, "/.*$", "다")) # 형태소 정보 제거
word_p_tb_book3 <- word_tb_book3 %>%
filter(str_detect(morp, "/p")) %>% # 동사, 형용사 추출
mutate(word = str_replace(morp, "/.*$", "다")) # 형태소 정보 제거
word_p_tb_book4 <- word_tb_book4 %>%
filter(str_detect(morp, "/p")) %>% # 동사, 형용사 추출
mutate(word = str_replace(morp, "/.*$", "다")) # 형태소 정보 제거
word_p_tb_book5 <- word_tb_book5 %>%
filter(str_detect(morp, "/p")) %>% # 동사, 형용사 추출
mutate(word = str_replace(morp, "/.*$", "다")) # 형태소 정보 제거
word_p_tb_book1 %>%
print(n = 20)
word_p_tb_book2 %>%
print(n = 20)
word_p_tb_book3 %>%
print(n = 20)
word_p_tb_book4 %>%
print(n = 20)
word_p_tb_book5 %>%
print(n = 20) 데이터 통합
# 통합 (시편)
word_t_tb <- bind_rows(word_n_tb, word_p_tb)
word_t_tb
# 통합 (창세기)
word_t_tb_genesis <- bind_rows(word_n_tb_genesis, word_p_tb_genesis)
word_t_tb_genesis
# 통합 (출애굽기)
word_t_tb_exodus <- bind_rows(word_n_tb_exodus, word_p_tb_exodus)
word_t_tb_exodus
# 통합 (레위기)
word_t_tb_leviticus <- bind_rows(word_n_tb_leviticus, word_p_tb_leviticus)
word_t_tb_leviticus
# 통합 (민수기)
word_t_tb_numbers <- bind_rows(word_n_tb_numbers, word_p_tb_numbers)
word_t_tb_numbers
# 통합 (신명기)
word_t_tb_deuteronomy <- bind_rows(word_n_tb_deuteronomy, word_p_tb_deuteronomy)
word_t_tb_deuteronomy
# BOOK # 통합
word_t_tb_book1 <- bind_rows(word_n_tb_book1, word_p_tb_book1)
word_t_tb_book1
word_t_tb_book2 <- bind_rows(word_n_tb_book2, word_p_tb_book2)
word_t_tb_book2
word_t_tb_book3 <- bind_rows(word_n_tb_book3, word_p_tb_book3)
word_t_tb_book3
word_t_tb_book4 <- bind_rows(word_n_tb_book4, word_p_tb_book4)
word_t_tb_book4
word_t_tb_book5 <- bind_rows(word_n_tb_book5, word_p_tb_book5)
word_t_tb_book5 단어 바꾸기
### 단어 정리
# 단어 바꾸기 (시편)
word_t_tb <- word_t_tb %>%
mutate(word = gsub("어호와", "여호와", word)) %>%
mutate(word = gsub("경외하", "경외하다", word))
word_t_tb
# 단어 바꾸기 (창세기)
word_t_tb_genesis <- word_t_tb_genesis %>%
mutate(word = gsub("어호와", "여호와", word)) %>%
mutate(word = gsub("경외하", "경외하다", word))
word_t_tb_genesis
# 단어 바꾸기 (출애굽기)
word_t_tb_exodus <- word_t_tb_exodus %>%
mutate(word = gsub("어호와", "여호와", word)) %>%
mutate(word = gsub("경외하", "경외하다", word))
word_t_tb_exodus
# 단어 바꾸기 (레위기)
word_t_tb_leviticus <- word_t_tb_leviticus %>%
mutate(word = gsub("어호와", "여호와", word)) %>%
mutate(word = gsub("경외하", "경외하다", word))
word_t_tb_leviticus
# 단어 바꾸기 (민수기)
word_t_tb_numbers <- word_t_tb_numbers %>%
mutate(word = gsub("어호와", "여호와", word)) %>%
mutate(word = gsub("경외하", "경외하다", word))
word_t_tb_numbers
# 단어 바꾸기 (신명기)
word_t_tb_deuteronomy <- word_t_tb_deuteronomy %>%
mutate(word = gsub("어호와", "여호와", word)) %>%
mutate(word = gsub("경외하", "경외하다", word))
word_t_tb_deuteronomy
# BOOK # 단어 바꾸기
word_t_tb_book1 <- word_t_tb_book1 %>%
mutate(word = gsub("어호와", "여호와", word)) %>%
mutate(word = gsub("경외하", "경외하다", word))
word_t_tb_book1
word_t_tb_book2 <- word_t_tb_book2 %>%
mutate(word = gsub("어호와", "여호와", word)) %>%
mutate(word = gsub("경외하", "경외하다", word))
word_t_tb_book2
word_t_tb_book3 <- word_t_tb_book3 %>%
mutate(word = gsub("어호와", "여호와", word)) %>%
mutate(word = gsub("경외하", "경외하다", word))
word_t_tb_book3
word_t_tb_book4 <- word_t_tb_book4 %>%
mutate(word = gsub("어호와", "여호와", word)) %>%
mutate(word = gsub("경외하", "경외하다", word))
word_t_tb_book4
word_t_tb_book5 <- word_t_tb_book5 %>%
mutate(word = gsub("어호와", "여호와", word)) %>%
mutate(word = gsub("경외하", "경외하다", word))
word_t_tb_book5 단어 삭제
# 단어 삭제
st_word <- tibble(word = c("저희", "저가", "자기", "아니하다", "못하다",
"인하다", "누구", "하사", "하나", "여기",
"거기", "말하기", "행하", "내리다", "그것")) 불용어 제거
# 불용어 제거 (시편)
word_t_tb <- word_t_tb %>%
anti_join(st_word, by = "word")
word_t_tb
# 불용어 제거 (창세기)
word_t_tb_genesis <- word_t_tb_genesis %>%
anti_join(st_word, by = "word")
word_t_tb_genesis
# 불용어 제거 (출애굽기)
word_t_tb_exodus <- word_t_tb_exodus %>%
anti_join(st_word, by = "word")
word_t_tb_exodus
# 불용어 제거 (레위기)
word_t_tb_leviticus <- word_t_tb_leviticus %>%
anti_join(st_word, by = "word")
word_t_tb_leviticus
# 불용어 제거 (민수기)
word_t_tb_numbers <- word_t_tb_numbers %>%
anti_join(st_word, by = "word")
word_t_tb_numbers
# 불용어 제거 (신명기)
word_t_tb_deuteronomy <- word_t_tb_deuteronomy %>%
anti_join(st_word, by = "word")
word_t_tb_deuteronomy
# BOOK # 불용어 제거
word_t_tb_book1 <- word_t_tb_book1 %>%
anti_join(st_word, by = "word")
word_t_tb_book1
word_t_tb_book2 <- word_t_tb_book2 %>%
anti_join(st_word, by = "word")
word_t_tb_book2
word_t_tb_book3 <- word_t_tb_book3 %>%
anti_join(st_word, by = "word")
word_t_tb_book3
word_t_tb_book4 <- word_t_tb_book4 %>%
anti_join(st_word, by = "word")
word_t_tb_book4
word_t_tb_book5 <- word_t_tb_book5 %>%
anti_join(st_word, by = "word")
word_t_tb_book5 아니하다: "아니하나이다"라는 말로 성경에서 흔하게 "합니다" 처럼 쓰이는 말이므로 삭제
하나: "저를 죽이고자 하나" 같은 말로 쓰였으나 숫자 하나와 혼동할 여지가 있어 삭제
혼동의 여지가 있거나, 흔하게 사용된 단어를 삭제하였다.
단어 빈도 및 퍼센테이지(%) 계산
### 단어 빈도 분석
# 단어 빈도 및 퍼센테이지(%) 계산 (시편)
word_count <- word_t_tb %>%
count(word, sort = TRUE) %>%
mutate(prop = n / sum(n)) %>%
ungroup()
word_count
# 단어 빈도 및 퍼센테이지(%) 계산 (창세기)
word_count_genesis <- word_t_tb_genesis %>%
count(word, sort = TRUE) %>%
mutate(prop = n / sum(n)) %>%
ungroup()
word_count_genesis
# 단어 빈도 및 퍼센테이지(%) 계산 (출애굽기)
word_count_exodus <- word_t_tb_exodus %>%
count(word, sort = TRUE) %>%
mutate(prop = n / sum(n)) %>%
ungroup()
word_count_exodus
# 단어 빈도 및 퍼센테이지(%) 계산 (레위기)
word_count_leviticus <- word_t_tb_leviticus %>%
count(word, sort = TRUE) %>%
mutate(prop = n / sum(n)) %>%
ungroup()
word_count_leviticus
# 단어 빈도 및 퍼센테이지(%) 계산 (민수기)
word_count_numbers <- word_t_tb_numbers %>%
count(word, sort = TRUE) %>%
mutate(prop = n / sum(n)) %>%
ungroup()
word_count_numbers
# 단어 빈도 및 퍼센테이지(%) 계산 (신명기)
word_count_deuteronomy <- word_t_tb_deuteronomy %>%
count(word, sort = TRUE) %>%
mutate(prop = n / sum(n)) %>%
ungroup()
word_count_deuteronomy
# BOOK # 단어 빈도 및 퍼센테이지(%) 계산
word_count_book1 <- word_t_tb_book1 %>%
count(word, sort = TRUE) %>%
mutate(prop = n / sum(n)) %>%
ungroup()
word_count_book1
word_count_book2 <- word_t_tb_book2 %>%
count(word, sort = TRUE) %>%
mutate(prop = n / sum(n)) %>%
ungroup()
word_count_book2
word_count_book3 <- word_t_tb_book3 %>%
count(word, sort = TRUE) %>%
mutate(prop = n / sum(n)) %>%
ungroup()
word_count_book3
word_count_book4 <- word_t_tb_book4 %>%
count(word, sort = TRUE) %>%
mutate(prop = n / sum(n)) %>%
ungroup()
word_count_book4
word_count_book5 <- word_t_tb_book5 %>%
count(word, sort = TRUE) %>%
mutate(prop = n / sum(n)) %>%
ungroup()
word_count_book5 단어 확인
# 단어 확인 (시편) (상위 100개 확인)
word_count %>%
slice_max(n, n = 100) %>%
print(n = 100)
# 단어 확인 (창세기)
word_count_genesis %>%
slice_max(n, n = 100) %>%
print(n = 100)
# 단어 확인 (출애굽기)
word_count_exodus %>%
slice_max(n, n = 100) %>%
print(n = 100)
# 단어 확인 (레위기)
word_count_leviticus %>%
slice_max(n, n = 100) %>%
print(n = 100)
# 단어 확인 (민수기)
word_count_numbers %>%
slice_max(n, n = 100) %>%
print(n = 100)
# 단어 확인 (신명기)
word_count_deuteronomy %>%
slice_max(n, n = 100) %>%
print(n = 100)
# BOOK # 단어 확인 (상위 100개 확인)
word_count_book1 %>%
slice_max(n, n = 100) %>%
print(n = 100)
word_count_book2 %>%
slice_max(n, n = 100) %>%
print(n = 100)
word_count_book3 %>%
slice_max(n, n = 100) %>%
print(n = 100)
word_count_book4 %>%
slice_max(n, n = 100) %>%
print(n = 100)
word_count_book5 %>%
slice_max(n, n = 100) %>%
print(n = 100)
# 단어 확인 (상위 50개 확인)
word_count %>%
slice_max(n, n = 50) %>%
print(n = 50)
# 단어 확인
# 특정 단어가 사용된 문장 추출
tm_tb %>%
filter(str_detect(verse, "하나님")) %>%
print(n = 20)
tm_tb %>%
filter(str_detect(verse, "우리")) %>%
print(n = 20)
tm_tb %>%
filter(str_detect(verse, "너희")) %>%
print(n = 20)
tm_tb %>%
filter(str_detect(verse, "할렐루야")) %>%
print(n = 20)
tm_tb %>%
filter(str_detect(verse, "사랑")) %>%
print(n = 20)
# BOOK # 단어 확인
psalter_book1 %>%
filter(str_detect(verse, "사랑")) %>%
print(n = 20)
psalter_book2 %>%
filter(str_detect(verse, "사랑")) %>%
print(n = 20)
psalter_book3 %>%
filter(str_detect(verse, "사랑")) %>%
print(n = 20)
psalter_book4 %>%
filter(str_detect(verse, "사랑")) %>%
print(n = 20)
psalter_book5 %>%
filter(str_detect(verse, "사랑")) %>%
print(n = 20) 단어 빈도 그래프
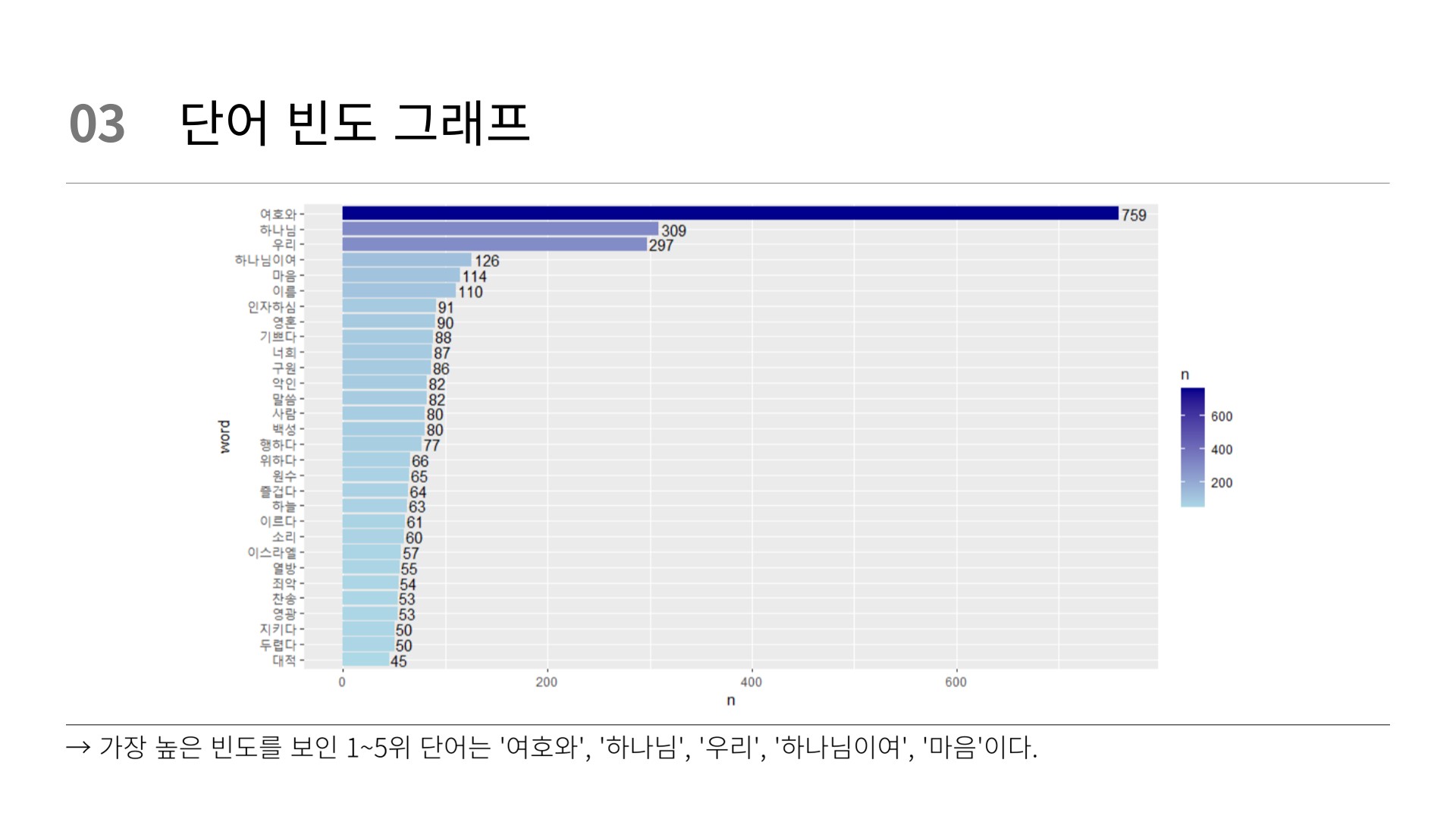
### 단어빈도 그래프
word_count %>%
mutate(word = reorder(word, n)) %>%
slice_max(n, n = 30) %>%
ggplot(mapping = aes(x = n, #n을 쓸지 prop을 쓸지 설정
y = word)) +
geom_text(aes(label = n), hjust = -0.1) +
geom_col()
### 단어빈도 그래프 색상변경
word_count %>%
mutate(word = reorder(word, n)) %>%
slice_max(n, n = 30) %>%
ggplot(mapping = aes(x = n,
y = word,
fill = n)) + # 빈도수에 따라 색상 변경
geom_text(aes(label = n), hjust = -0.1) +
geom_col() +
scale_fill_gradient(low = "lightblue", high = "darkblue") # 색상 매핑 설정
# BOOK # 단어빈도 그래프 색상변경
word_count_book1 %>%
mutate(word = reorder(word, n)) %>%
slice_max(n, n = 20) %>%
ggplot(mapping = aes(x = n, #n을 쓸지 prop을 쓸지 설정
y = word)) +
geom_text(aes(label = n), hjust = -0.1) +
geom_col()
word_count_book2 %>%
mutate(word = reorder(word, n)) %>%
slice_max(n, n = 20) %>%
ggplot(mapping = aes(x = n, #n을 쓸지 prop을 쓸지 설정
y = word)) +
geom_text(aes(label = n), hjust = -0.1) +
geom_col()
word_count_book3 %>%
mutate(word = reorder(word, n)) %>%
slice_max(n, n = 20) %>%
ggplot(mapping = aes(x = n, #n을 쓸지 prop을 쓸지 설정
y = word)) +
geom_text(aes(label = n), hjust = -0.1) +
geom_col()
word_count_book4 %>%
mutate(word = reorder(word, n)) %>%
slice_max(n, n = 20) %>%
ggplot(mapping = aes(x = n, #n을 쓸지 prop을 쓸지 설정
y = word)) +
geom_text(aes(label = n), hjust = -0.1) +
geom_col()
word_count_book5 %>%
mutate(word = reorder(word, n)) %>%
slice_max(n, n = 20) %>%
ggplot(mapping = aes(x = n, #n을 쓸지 prop을 쓸지 설정
y = word)) +
geom_text(aes(label = n), hjust = -0.1) +
geom_col() 워드클라우드
# === 워드클라우드 === #
# 검은색 워드클라우드
set.seed(123)
word_count %>%
filter(n > 20) %>%
ggplot(mapping = aes(label = word,
size = n)) +
geom_text_wordcloud_area() +
scale_size_area(max_size = 30) +
theme_minimal() +
theme(panel.background = element_rect(fill = "white"))
# 단색 워드클라우드
set.seed(123)
word_count %>%
slice_max(prop, n = 100) %>%
ggplot(mapping = aes(label = word,
size = prop,
color = prop)) +
geom_text_wordcloud_area() +
scale_size_area(max_size = 30) +
scale_color_gradient(low = "darkblue", high = "blue") +
theme(panel.background = element_rect(fill = "white"))
# BOOK # 단색 워드클라우드
set.seed(123)
word_count_book1 %>%
slice_max(prop, n = 50) %>%
ggplot(mapping = aes(label = word,
size = prop,
color = prop)) +
geom_text_wordcloud_area() +
scale_size_area(max_size = 30) +
scale_color_gradient(low = "navy", high = "lightblue") +
theme(panel.background = element_rect(fill = "white"))
set.seed(123)
word_count_book2 %>%
slice_max(prop, n = 50) %>%
ggplot(mapping = aes(label = word,
size = prop,
color = prop)) +
geom_text_wordcloud_area() +
scale_size_area(max_size = 30) +
scale_color_gradient(low = "navy", high = "lightblue") +
theme(panel.background = element_rect(fill = "white"))
set.seed(123)
word_count_book3 %>%
slice_max(prop, n = 50) %>%
ggplot(mapping = aes(label = word,
size = prop,
color = prop)) +
geom_text_wordcloud_area() +
scale_size_area(max_size = 30) +
scale_color_gradient(low = "navy", high = "lightblue") +
theme(panel.background = element_rect(fill = "white"))
set.seed(123)
word_count_book4 %>%
slice_max(prop, n = 50) %>%
ggplot(mapping = aes(label = word,
size = prop,
color = prop)) +
geom_text_wordcloud_area() +
scale_size_area(max_size = 30) +
scale_color_gradient(low = "navy", high = "lightblue") +
theme(panel.background = element_rect(fill = "white"))
set.seed(123)
word_count_book5 %>%
slice_max(prop, n = 50) %>%
ggplot(mapping = aes(label = word,
size = prop,
color = prop)) +
geom_text_wordcloud_area() +
scale_size_area(max_size = 30) +
scale_color_gradient(low = "navy", high = "lightblue") +
theme(panel.background = element_rect(fill = "white"))
# 무작위 색상 생성
set.seed(123)
color <- sample.int(n = 50,
size = nrow(word_count %>%
slice_max(n, n = 50)),
replace = TRUE)
# 무작위 색상 생성
set.seed(123)
color <- sample.int(n = 50,
size = nrow(word_count %>%
slice_max(n, n = 50)),
replace = TRUE)
# 여러 색 워드클라우드
set.seed(123)
color <- sample.int(n = 20, # 색 갯수 지정
size = nrow(word_count %>%
filter(n > 20)), # 단어에 색 넣기.
replace = TRUE)
word_count %>%
filter(n > 20) %>% # 위 color의 size의 filter n>20과 같아야 함
ggplot(mapping = aes(label = word,
size = n,
color = factor(color))) +
geom_text_wordcloud_area() +
scale_size_area(max_size = 33) +
theme_minimal()
# 여러 색 워드클라우드 + 폰트 수정
# windowsFonts(font=windowsFont("맑은 고딕"))
word_count %>%
filter(n > 20) %>% # 위 color의 size의 filter n>20과 같아야 함
ggplot(mapping = aes(label = word,
size = n,
color = factor(color))) +
geom_text_wordcloud(family = "맑은 고딕") +
geom_text_wordcloud_area() +
scale_size_area(max_size = 30) +
theme_minimal() +
theme(panel.background = element_rect(fill = "white")) word_count에서 가장 많이 등장하는 단어 상위 50개를 무작위로 선택하고, 그 개수에 맞게 임의의 색상을 생성한다. 이 작업은 후속 시각화 작업이나 데이터 표현을 위해 각 단어에 임의의 색상을 부여하기 위한 것이다.
동시출현단어(n 기준) 빈도분석
# === Co-occurrence(동시발생빈도) 의미연결망분석 === #
# 동시출현단어(n 기준) 빈도분석
word_pairs <- word_t_tb %>%
group_by(word) %>%
filter(n() >= 30) %>%
ungroup() %>%
pairwise_count(item = word,
feature = page,
sort = T)
word_pairs %>%
print(n = 20) word_pairs 데이터프레임
word_t_tb 데이터프레임에서 등장 빈도가 30 이상인 단어들을 선택한다.
pairwise_count() 함수를 사용하여 단어 간의 등장 관계를 계산한다.
이때, item 매개변수에는 단어를, feature 매개변수에는 페이지 번호를 지정한다.
결과는 item1, item2, n 열로 구성된 표로, 각 단어 쌍의 등장 횟수를 나타낸다.
이는 단어 간의 연관성을 파악하기 위해 사용된다.
동시출현단어(cor 기준) 상관계수분석
# 동시출현단어(cor 기준) 상관계수분석
word_cors <- word_t_tb %>%
group_by(word) %>%
filter(n() >= 30) %>%
ungroup() %>%
pairwise_cor(item = word,
feature = page,
sort = T)
word_cors %>%
print(n = 20) word_cors 데이터프레임
word_t_tb 데이터프레임에서 등장 빈도가 30 이상인 단어들을 선택한다.
pairwise_cor() 함수를 사용하여 단어 간의 상관관계를 계산한다.
이때, item 매개변수에는 단어를, feature 매개변수에는 페이지 번호를 지정한다.
결과는 item1, item2, correlation 열로 구성된 표로, 각 단어 쌍의 상관관계를 나타낸다.
이는 단어 간의 의미적 연결성을 파악하기 위해 사용된다.
word_pairs는 두 단어가 함께 등장한 횟수를 계산하여 단어 간의 연관성을 확인하고, word_cors는 단어 간의 상관관계를 계산하여 의미적 연결성을 파악한다.
단어 간의 연관성은 통계적인 관계를 중심으로 분석되며, 두 단어가 함께 등장하는 경향을 나타내는 반면, 의미적 연결성은 단어들의 의미나 주제와 관련하여 분석되며, 단어들 간의 의미적 유사성을 파악한다.
동시발생빈도 시각화
# === 동시발생빈도 시각화 === #
# centrality 확인
# Degree centrality(연결 중심성)
set.seed(123)
word_pairs_graph <- word_pairs %>%
filter(n >= 10) %>%
as_tbl_graph(directed = F) %>%
mutate(cent_dgr = centrality_degree(),
cent_btw = centrality_betweenness(),
cent_cls = centrality_closeness(),
cent_egn = centrality_eigen(),
cent_pg = centrality_pagerank(),
group = as.factor(group_infomap()))
word_pairs_graph
# table형식으로 엑셀에 저장
as_tibble(word_pairs_graph) %>%
arrange(desc(cent_dgr)) %>%
head(n=100) %>%
write_excel_csv("psalter_verses_word_pairs_graph.xls")
# 동시발생빈도 시각화
# 기본테이블 그래프
word_pairs %>%
slice_max(n, n = 100) %>%
as_tbl_graph(directed = F) %>%
ggraph(layout = "fr") +
geom_edge_link() +
geom_node_point() +
geom_node_text(mapping = aes(label = name),
vjust = 1,
hjust = 1)
# ggraph(layout = "fr"): 회색 기본 레이아웃 생성
# geom_edge_link(): 노드와 노드간의 연결선을 화면에 생성
# geom_node_point(): 노드의 점을 화면에 생성
# geom_node_text(aes(label = name): 노드의 이름을 화면에 생성
# vjust = 1, hjust = 1: 텍스트를 점의 x축, y축에서 거리를 두게 함
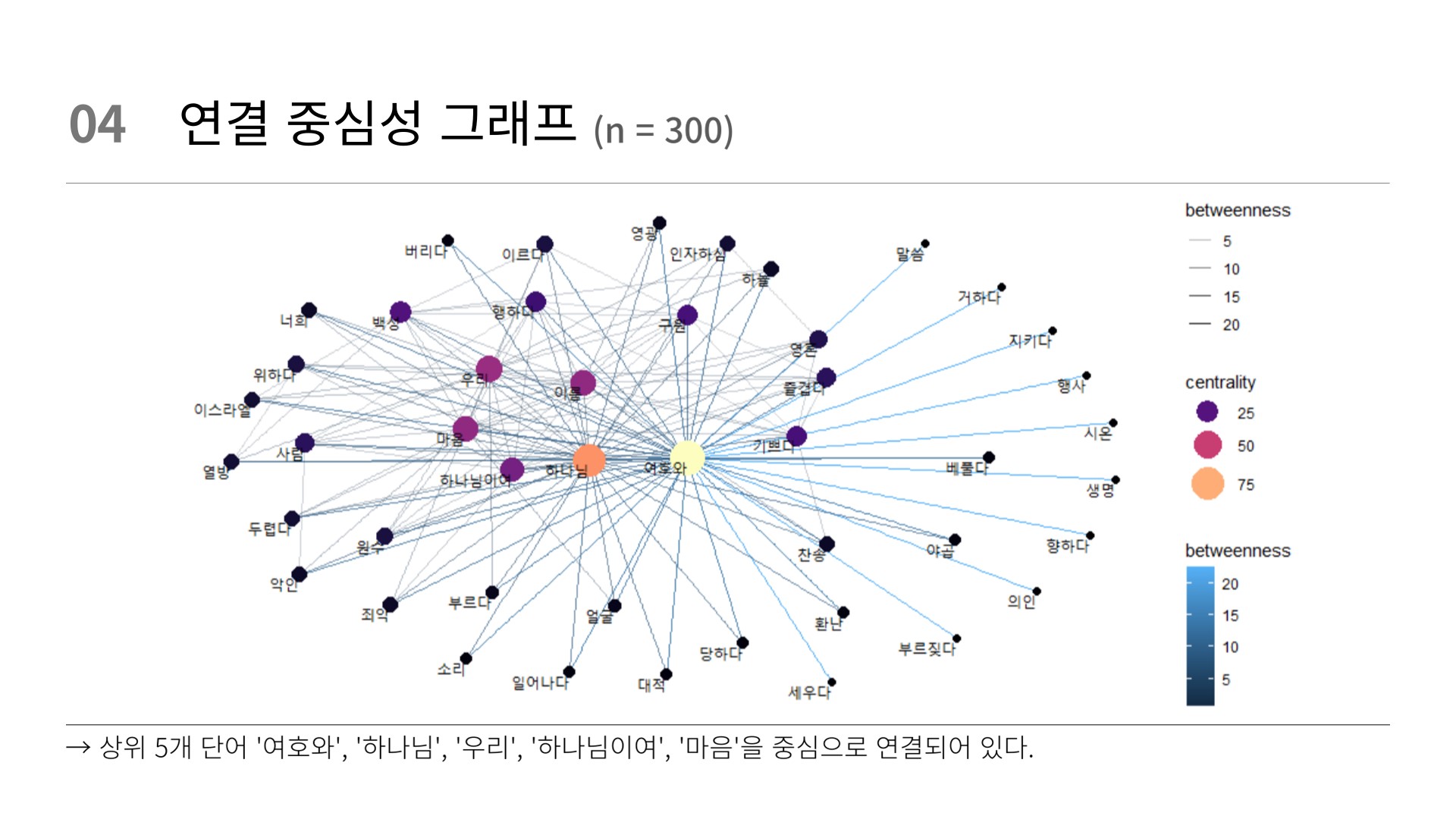
# 연결중심성 그래프
word_pairs_graph %>%
as_tbl_graph(directed = F) %>%
ggraph(layout = "fr") +
geom_edge_link() +
geom_node_point(mapping = aes(size = cent_dgr)) +
geom_node_text(mapping = aes(label = name),
vjust = 1,
hjust = 1)
# 연결중심 그래프 (색)
word_pairs %>%
slice_max(n, n = 100) %>%
as_tbl_graph(directed = F) %>%
activate(nodes) %>%
mutate(centrality = centrality_degree()) %>%
activate(edges) %>%
mutate(betweenness = centrality_edge_betweenness()) %>%
ggraph(layout = 'kk') + # 여기서부터는 ggraph의 파트이므로 +로 연결
geom_edge_link(aes(alpha = betweenness)) + # 색깔을 betweenness로 설정
geom_node_point(aes(size = centrality,
colour = centrality)) +
scale_color_continuous(guide = 'legend') +
geom_node_text(aes(label = name),
vjust = 1,
hjust = 1) +
theme_graph()
# betweenness: 중간, 사이
# centrality: 중심
# 연결중심그래프 다양한 색상
set.seed(123)
word_pairs %>%
slice_max(n, n = 300) %>%
as_tbl_graph(directed = F) %>%
activate(nodes) %>%
mutate(centrality = centrality_degree()) %>%
activate(edges) %>%
mutate(betweenness = centrality_edge_betweenness()) %>%
ggraph(layout = 'kk') +
geom_edge_link(aes(alpha = betweenness, color = betweenness)) +
geom_node_point(aes(size = centrality, color = centrality)) +
scale_color_viridis(option = "magma", guide = "legend") + # viridis 팔레트 및 option 설정
scale_size_continuous(range = c(2, 10)) + # 노드 크기 범위 조정
geom_node_text(aes(label = name), vjust = 1, hjust = 1) +
theme_graph()
# pagelink 그래프
word_pairs %>%
slice_max(n, n = 100) %>%
as_tbl_graph(directed = F) %>%
activate(nodes) %>%
mutate(similarity = node_similarity_with(which.max(centrality_pagerank()))) %>%
ggraph(layout = 'kk') +
geom_edge_link(colour = "pink") +
geom_node_point(aes(size = similarity), colour = 'steelblue') +
geom_node_text(aes(label = name), vjust = 1, hjust = 1) +
theme_graph()
word_pairs %>%
slice_max(n, n = 200) %>%
as_tbl_graph(directed = F) %>%
activate(nodes) %>%
mutate(centrality = centrality_degree()) %>%
activate(edges) %>%
mutate(betweenness = centrality_edge_betweenness()) %>%
ggraph(layout = 'kk') +
geom_edge_link(aes(alpha = betweenness, color = betweenness)) +
geom_node_point(aes(size = centrality, color = centrality)) +
scale_color_viridis(option = "magma", guide = "legend") +
scale_size_continuous(range = c(2, 10)) +
geom_node_text(aes(label = name), vjust = 1, hjust = 1, size = 5) +
theme_graph()
# 여러 색 그래프
arrow <- grid::arrow(type = "closed",
length = unit(.05, "inches"))
word_pairs_graph %>%
ggraph(layout = "fr") +
geom_edge_link(edge_color = "darkred",
arrow = arrow,
show.legend = FALSE) +
geom_node_point(aes(size = cent_dgr, # 노드 크기
color = group),
show.legend = FALSE) +
geom_node_text(aes(label = name),
repel = TRUE, # repel =TRUE: 텍스트가 겹치지 않게
point.padding = unit(0.2, "lines")) +
theme_void() # 격자 없애기
tm_tb %>%
filter(str_detect(verse, "하나님")) %>%
print(n = 20)
# 하위단어 분석
word_pairs %>%
filter(item1 == "나팔")
word_pairs %>%
filter(item1 == "영광")
word_pairs %>%
filter(item1 == "하나님")
word_pairs %>%
filter(item1 == "하나님이여")
word_pairs %>%
filter(item1 == "죄악")
word_pairs %>%
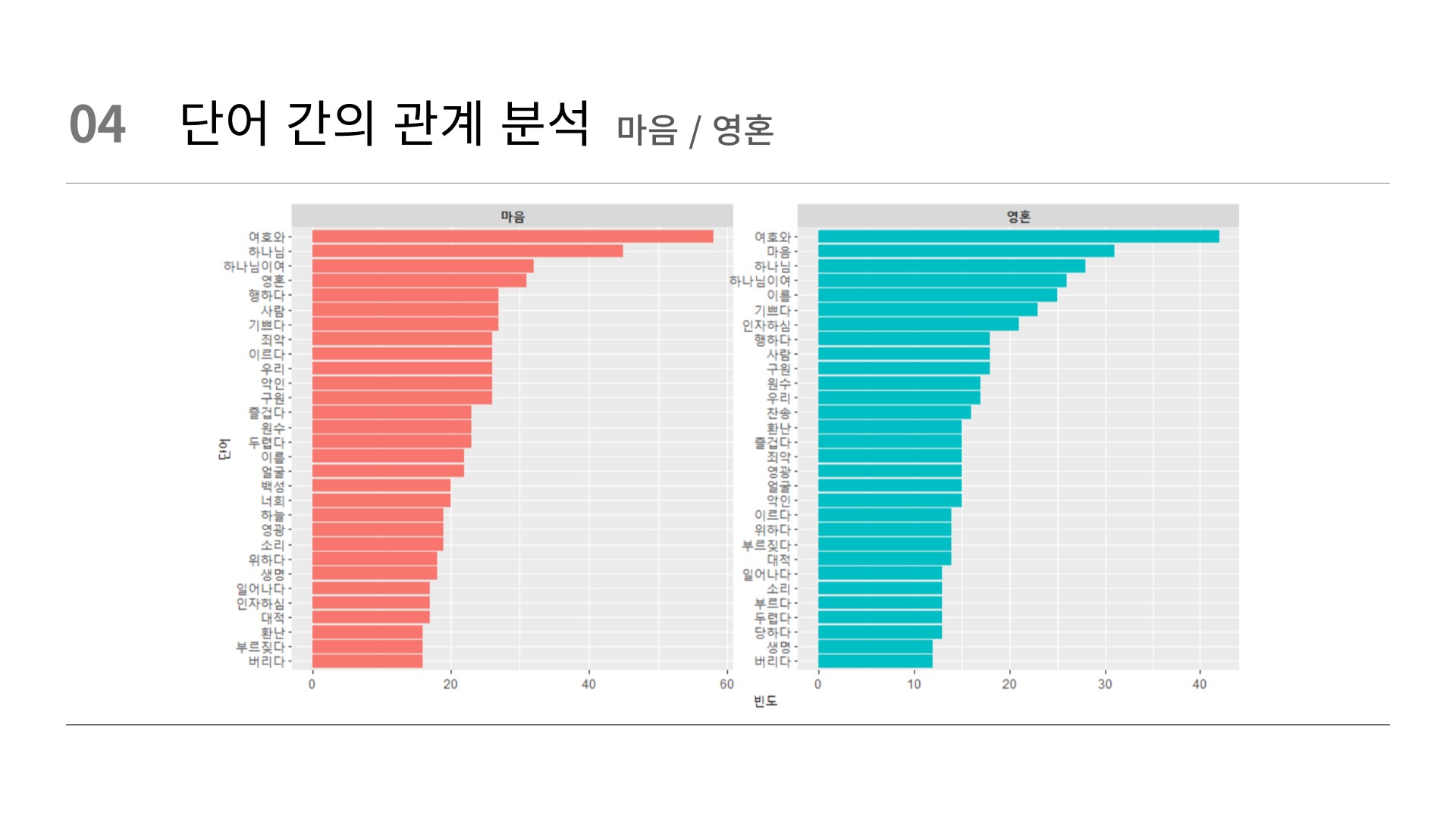
filter(item1 %in% c("마음", "영혼")) %>%
group_by(item1) %>%
slice_max(n, n = 30) %>%
ungroup() %>%
mutate(item2 = reorder_within(item2, n, item1)) %>%
ggplot(aes(x = n,
y = item2,
fill = item1)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ item1,
ncol = 2,
scales = "free") +
scale_y_reordered()
word_pairs %>%
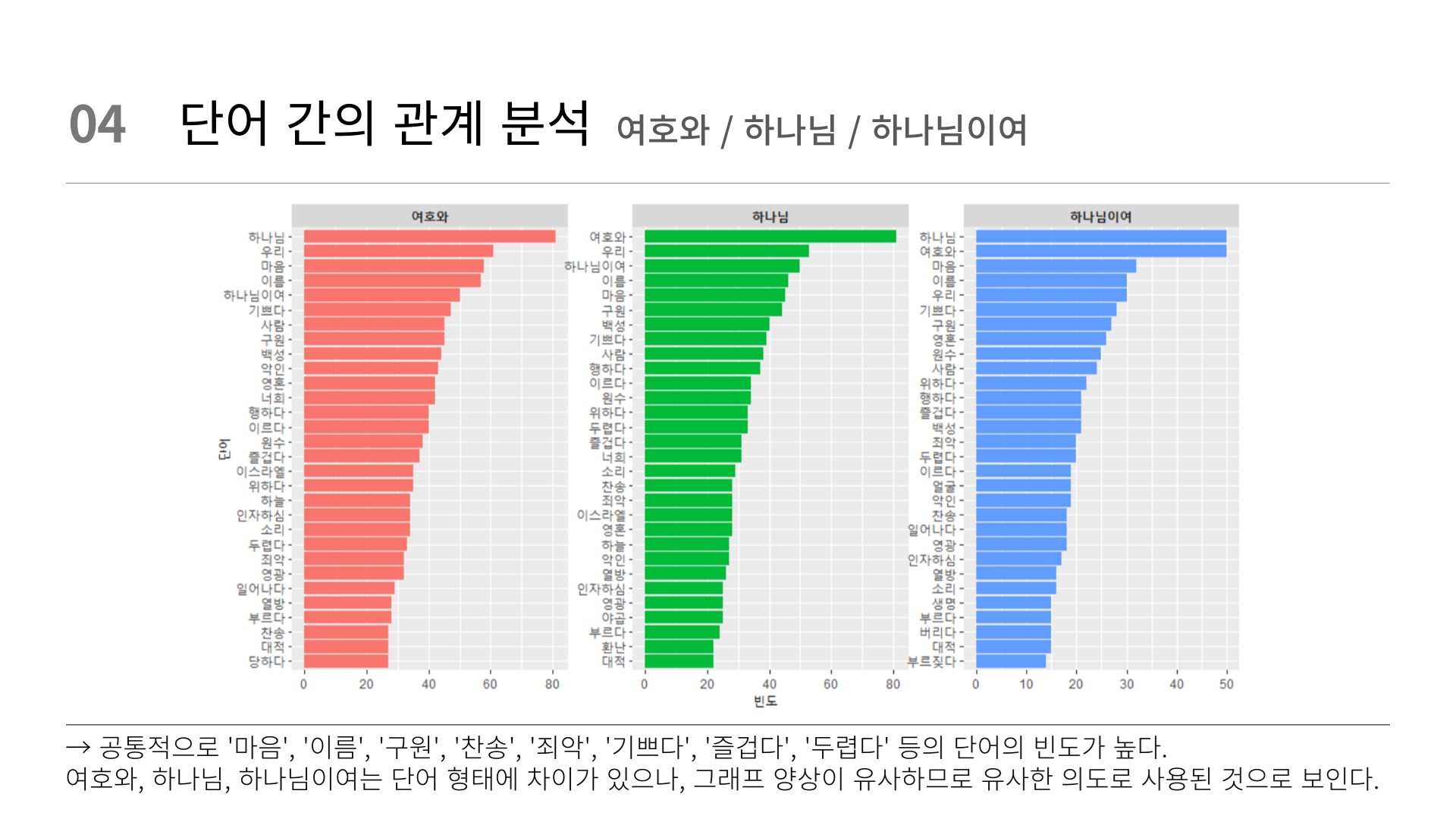
filter(item1 %in% c("여호와", "하나님", "하나님이여")) %>%
group_by(item1) %>%
slice_max(n, n = 30) %>%
ungroup() %>%
mutate(item2 = reorder_within(item2, n, item1)) %>%
ggplot(aes(x = n,
y = item2,
fill = item1)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ item1,
ncol = 3,
scales = "free") +
scale_y_reordered() +
labs(x = "빈도",
y = "단어")+
theme(strip.text = element_text(face = "bold"))
word_pairs %>%
filter(item1 %in% c("마음", "영혼")) %>%
group_by(item1) %>%
slice_max(n, n = 30) %>%
ungroup() %>%
mutate(item2 = reorder_within(item2, n, item1)) %>%
ggplot(aes(x = n,
y = item2,
fill = item1)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ item1,
ncol = 2,
scales = "free") +
scale_y_reordered() +
labs(x = "빈도",
y = "단어")+
theme(strip.text = element_text(face = "bold"))
word_pairs %>%
filter(item1 %in% c("소리", "아멘")) %>%
group_by(item1) %>%
slice_max(n, n = 30) %>%
ungroup() %>%
mutate(item2 = reorder_within(item2, n, item1)) %>%
ggplot(aes(x = n,
y = item2,
fill = item1)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ item1,
ncol = 2,
scales = "free") +
scale_y_reordered() +
labs(x = "빈도",
y = "단어")+
theme(strip.text = element_text(face = "bold"))
word_pairs %>%
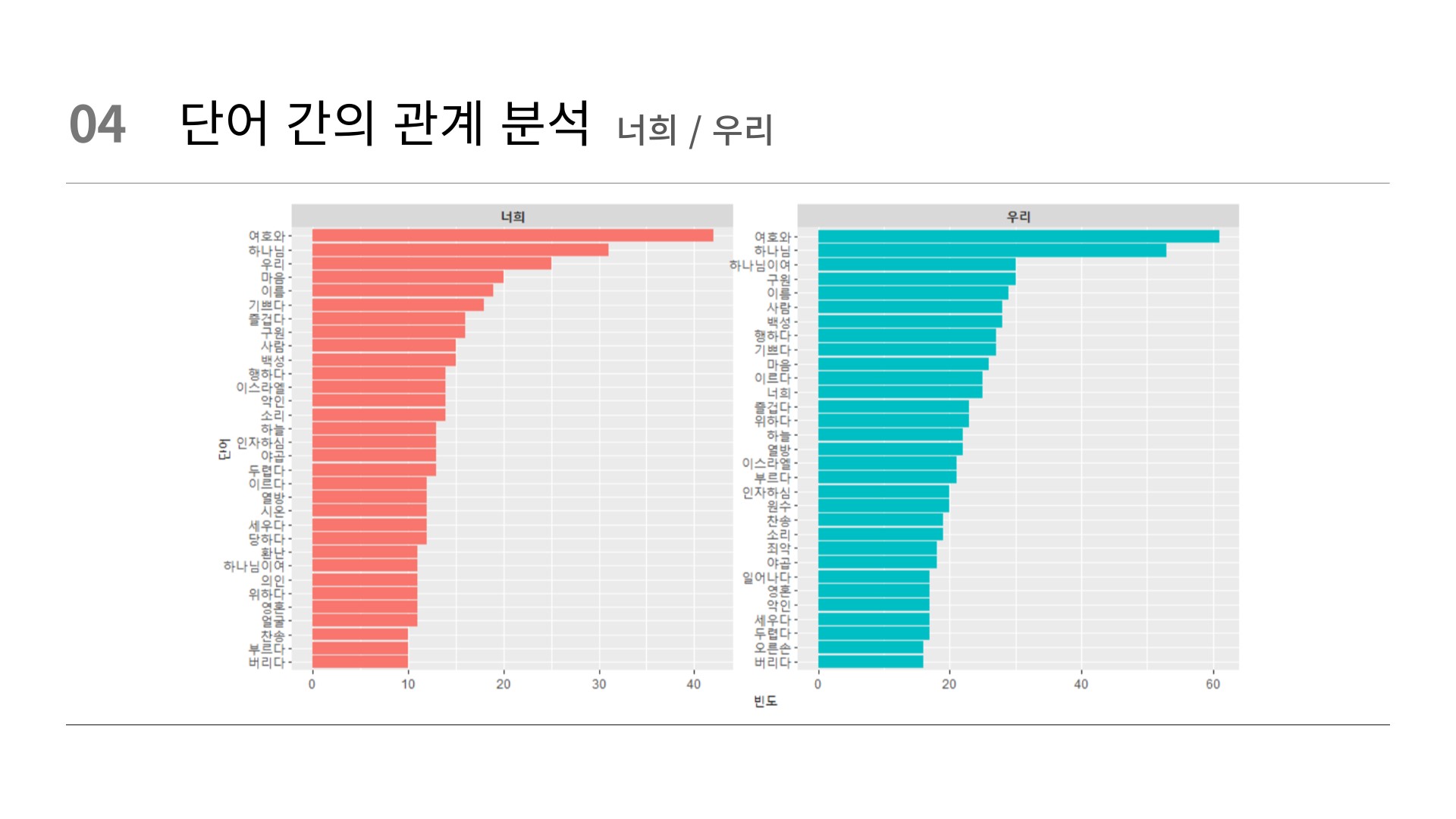
filter(item1 %in% c("너희", "우리")) %>%
group_by(item1) %>%
slice_max(n, n = 30) %>%
ungroup() %>%
mutate(item2 = reorder_within(item2, n, item1)) %>%
ggplot(aes(x = n,
y = item2,
fill = item1)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ item1,
ncol = 2,
scales = "free") +
scale_y_reordered() +
labs(x = "빈도",
y = "단어")+
theme(strip.text = element_text(face = "bold"))
word_pairs %>%
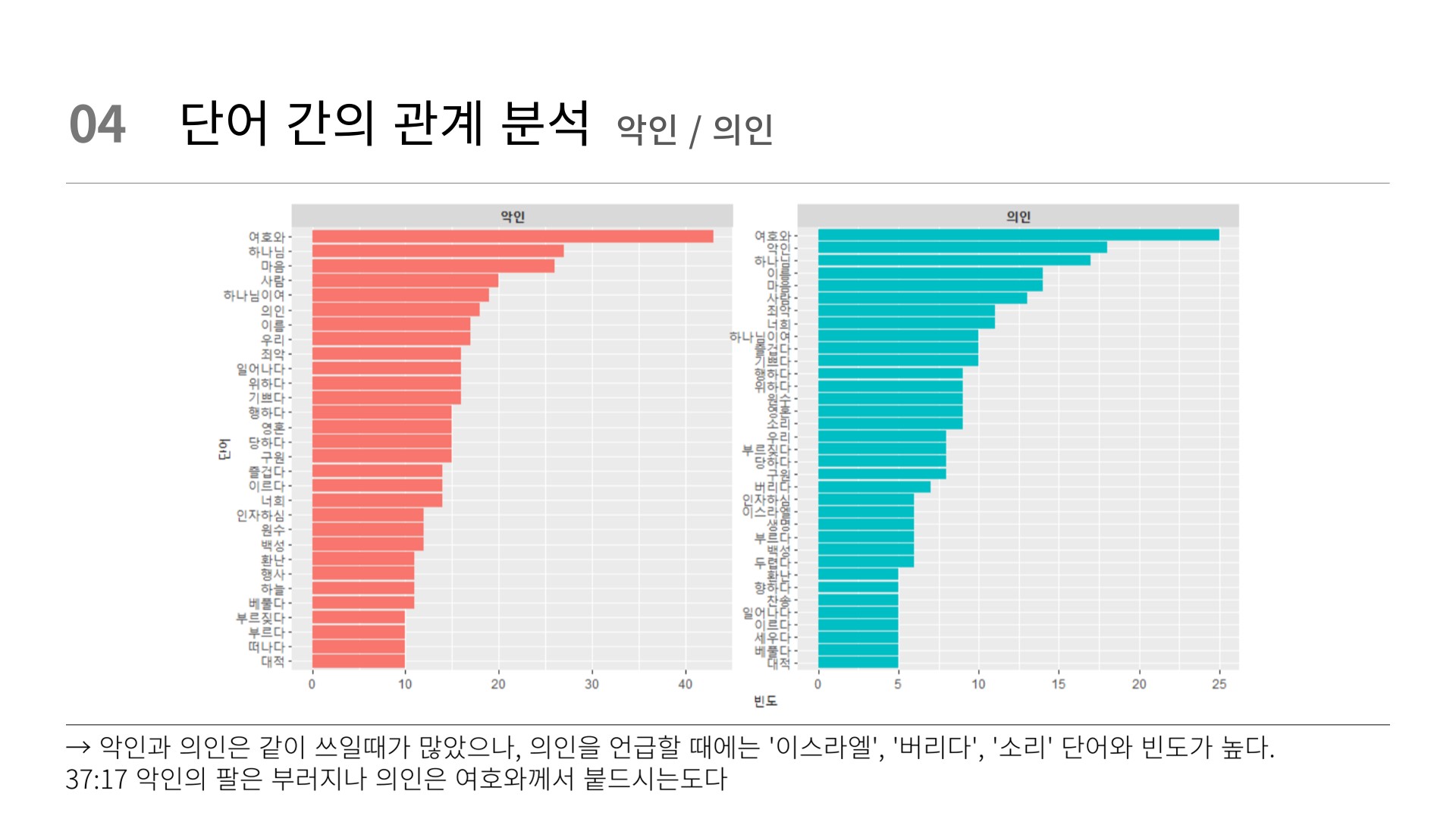
filter(item1 %in% c("악인", "의인")) %>%
group_by(item1) %>%
slice_max(n, n = 30) %>%
ungroup() %>%
mutate(item2 = reorder_within(item2, n, item1)) %>%
ggplot(aes(x = n,
y = item2,
fill = item1)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ item1,
ncol = 2,
scales = "free") +
scale_y_reordered() +
labs(x = "빈도",
y = "단어")+
theme(strip.text = element_text(face = "bold"))
# 학습과 가장 많이 나타나는 단어와 상관관계가 높은 단어
# show.legend = FALSE: 범례 삭제
# scales = "free"): sclaes를 free로 하므로 별개로 나온다
# 상위 50위 이내에서 보여주는 것이 좋다. (단어 개수는 50~100개)
word_pairs %>%
filter(item1 %in% c("하나님", "하나님이여")) %>%
group_by(item1) %>%
slice_max(n, n = 20) %>%
ungroup() %>%
mutate(item2 = reorder_within(item2, n, item1)) %>%
ggplot(aes(x = n,
y = item2,
fill = item1)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ item1,
ncol = 2,
scales = "free") +
scale_y_reordered()
word_pairs %>%
filter(item1 %in% c("너희", "우리")) %>%
group_by(item1) %>%
slice_max(n, n = 20) %>%
ungroup() %>%
mutate(item2 = reorder_within(item2, n, item1)) %>%
ggplot(aes(x = n,
y = item2,
fill = item1)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ item1,
ncol = 2,
scales = "free") +
scale_y_reordered()
word_pairs %>%
filter(item1 %in% c("악인", "의인")) %>%
group_by(item1) %>%
slice_max(n, n = 20) %>%
ungroup() %>%
mutate(item2 = reorder_within(item2, n, item1)) %>%
ggplot(aes(x = n,
y = item2,
fill = item1)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ item1,
ncol = 2,
scales = "free") +
scale_y_reordered()
word_pairs %>%
filter(item1 %in% c("기쁘다", "즐겁다", "부르다")) %>%
group_by(item1) %>%
slice_max(n, n = 20) %>%
ungroup() %>%
mutate(item2 = reorder_within(item2, n, item1)) %>%
ggplot(aes(x = n,
y = item2,
fill = item1)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ item1,
ncol = 3,
scales = "free") +
scale_y_reordered() 문서-단어(dtm) 행렬 만들기
# === 토픽 분석 === #
# 문서-단어(dtm) 행렬 만들기
# tf-idf 만들기
word_t_idf <- word_t_tb %>%
count(page, word, sort = T) %>%
bind_tf_idf(word, page, n)
# dfm 만들기
word_dfm <- word_t_idf %>%
cast_dfm(document = page,
term = word,
value = n) 토픽모델 생성
# 최적 토픽수 찾기
# 토픽모델 생성
set.seed(123)
topic_models <- data_frame(K = c(5, 10, 15, 20, 30)) %>%
mutate(topic_model = future_map(K, ~stm(word_dfm,
K = .,
verbose = F)))
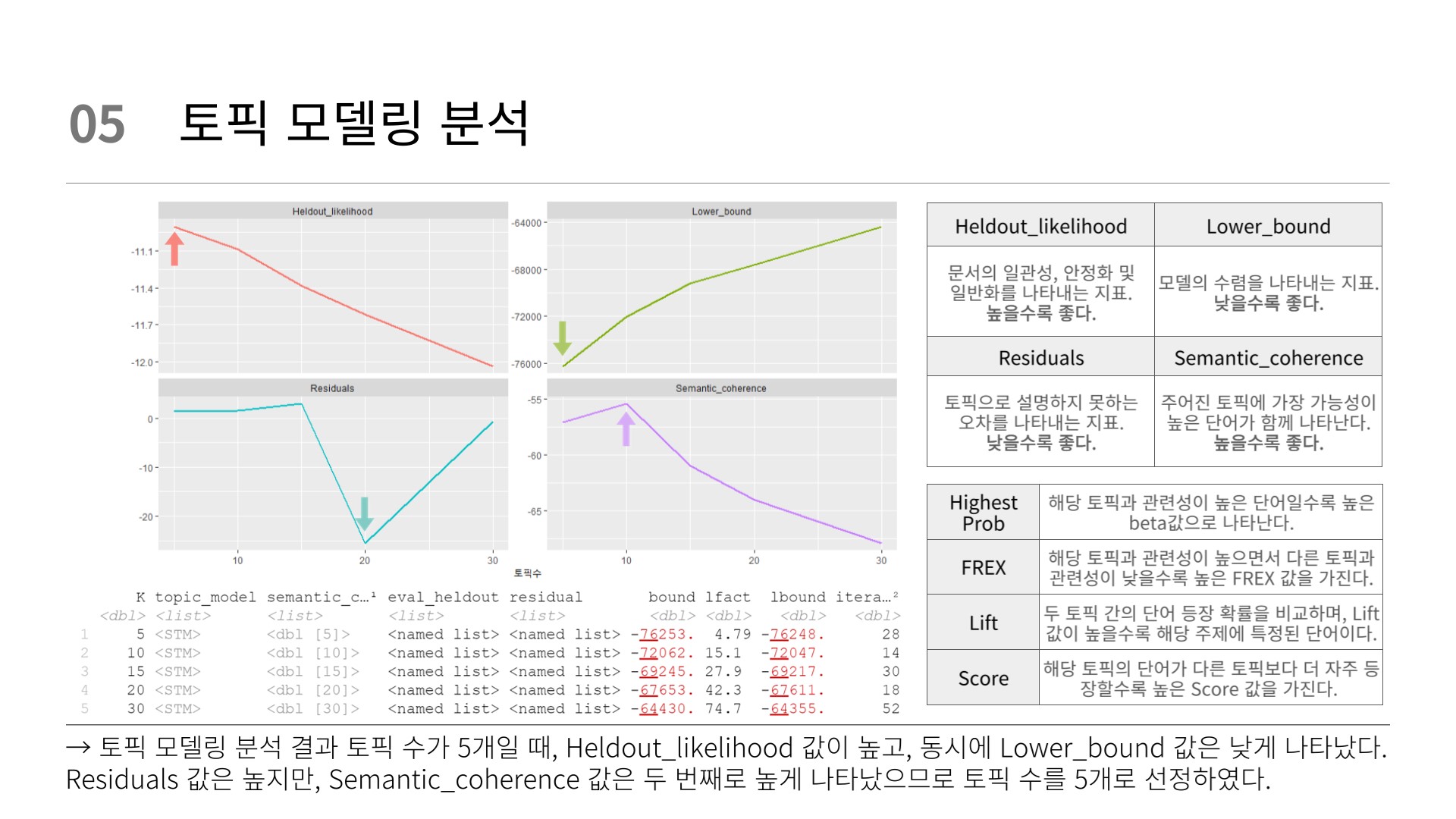
topic_models 토픽모델 평가
# 토픽모델 평가
heldout <- make.heldout(word_dfm)
topic_result <- topic_models %>%
mutate(semantic_coherence = map(topic_model,
semanticCoherence,
word_dfm),
eval_heldout = map(topic_model,
eval.heldout,
heldout$missing),
residual = map(topic_model,
checkResiduals,
word_dfm),
bound = map_dbl(topic_model,
function(x) max(x$convergence$bound)),
lfact = map_dbl(topic_model,
function(x) lfactorial(x$settings$dim$K)),
lbound = bound + lfact,
iterations = map_dbl(topic_model,
function(x) length(x$convergence$bound)))
topic_result K: 토픽의 개수
topic_model: 토픽 모델 객체
semantic_coherence: 토픽 모델의 의미 일관성 지표
eval_heldout: 테스트 데이터 세트에 대한 평가 결과
residual: 토픽 모델의 잔차
bound: 모델링 과정에서 최대화되는 경계값
lfact: 토픽의 개수에 따른 lfactorial 값
lbound: 경계값과 lfactorial 값을 합한 값
iterations: 최적화 과정에서 수행된 반복 횟수
토픽분석결과 그래프
# 토픽분석결과 그래프
topic_result %>%
transmute(K,
Lower_bound = lbound,
Residuals = map_dbl(residual,
"dispersion"),
Semantic_coherence = map_dbl(semantic_coherence,
mean),
Heldout_likelihood = map_dbl(eval_heldout,
"expected.heldout")) %>%
gather(Metric, Value, -K) %>%
ggplot(mapping = aes(x = K,
y = Value,
color = Metric)) +
geom_line(size = 1,
show.legend = FALSE) +
facet_wrap(~ Metric, scales = "free_y") +
labs(x = "토픽수",
y = NULL) 최적 토픽 결정
# best 토픽 결정
# 최적 토픽 결정
best_model <- topic_result %>%
filter(K == 5) %>%
pull(topic_model) %>%
.[[1]] # 리스트로 되어 있는 부분 제거
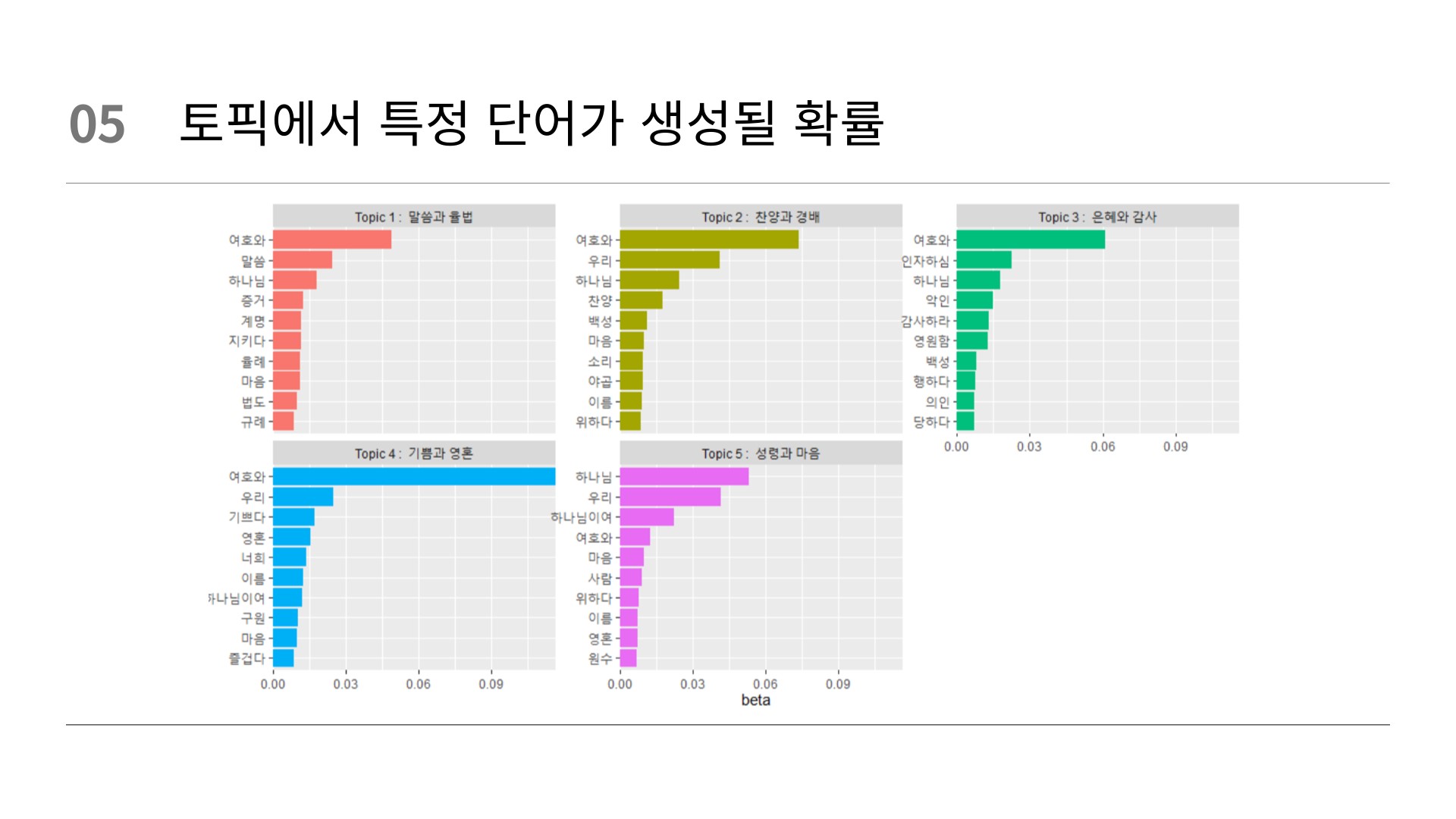
# 토픽별 단어 확인
summary(best_model)
# beta 특정 토픽에서 특정단어가 생성될 확률(beta)
# 토픽별 beta 확인
word_beta <- tidy(best_model,
matrix = "beta")
word_beta 토픽별 beta 그래프
# 토픽별 beta 그래프
word_beta %>%
group_by(topic) %>%
slice_max(beta, n = 10) %>%
ungroup() %>%
mutate(topic = paste("Topic", topic)) %>%
ggplot(mapping = aes(x = beta,
y = reorder_within(term, beta, topic),
fill = topic)) +
geom_col(show.legend = FALSE) +
facet_wrap(vars(topic), scales = "free_y") +
scale_x_continuous(expand = c(0, 0)) +
scale_y_reordered() +
labs(y = NULL)
# 토픽별 beta 그래프 (토픽 이름)
word_beta %>%
group_by(topic) %>%
slice_max(beta, n = 10) %>%
ungroup() %>%
mutate(topic = paste("Topic", topic, ": ",
case_when(
topic == 1 ~ "말씀과 율법",
topic == 2 ~ "찬양과 경배",
topic == 3 ~ "은혜와 감사",
topic == 4 ~ "기쁨과 영혼",
topic == 5 ~ "성령과 마음",
TRUE ~ "Unknown"
))) %>%
ggplot(mapping = aes(x = beta,
y = reorder_within(term, beta, topic),
fill = topic)) +
geom_col(show.legend = FALSE) +
facet_wrap(vars(topic), scales = "free_y") +
scale_x_continuous(expand = c(0, 0)) +
scale_y_reordered() +
labs(y = NULL)
# topic별 beta 상대비교
beta_wide <- word_beta %>%
group_by(topic) %>%
slice_max(beta, n=10) %>%
ungroup() %>%
arrange(topic, -beta)
beta_wide %>%
mutate(topic = paste0("topic", topic)) %>% # 토픽번호 수정 1->topic1
pivot_wider(names_from = topic,
values_from = beta) %>%
print(n=74)
# 특정 문서가 특정 토픽을 반영할 확률 (gamma)
# gamma 확인
word_gamma <- tidy(best_model,
matrix = "gamma",
document_names = rownames(word_dfm))
word_gamma
# 문서별 관련 토픽 그래프
word_gamma %>%
mutate(docement = fct_reorder(document, gamma),
topic = factor(topic)) %>%
ggplot(mapping = aes(x = gamma,
y = topic,
fill = topic)) +
geom_col(show.legend = FALSE) +
facet_wrap(vars(docement), ncol = 4) +
scale_x_continuous(expand = c(0, 0)) +
labs(y = NULL)
# 문서별 관련 토픽 확률
word_gamma %>%
mutate(topic = paste0("topic", topic)) %>%
pivot_wider(names_from = topic, # 토픽번호 수정 1->topic1
values_from = gamma) %>%
print(n=20)
output_file <- "Psalter_verses_gamma.xls"
write_excel_csv(word_gamma, path = output_file)
# 원하는 문서만 확인
word_gamma %>%
mutate(topic = paste0("topic", topic)) %>% # 토픽번호 수정 1->topic1
pivot_wider(names_from = topic,
values_from = gamma) %>%
filter(document == 1) 토픽별 단어, 문서 분포 통합
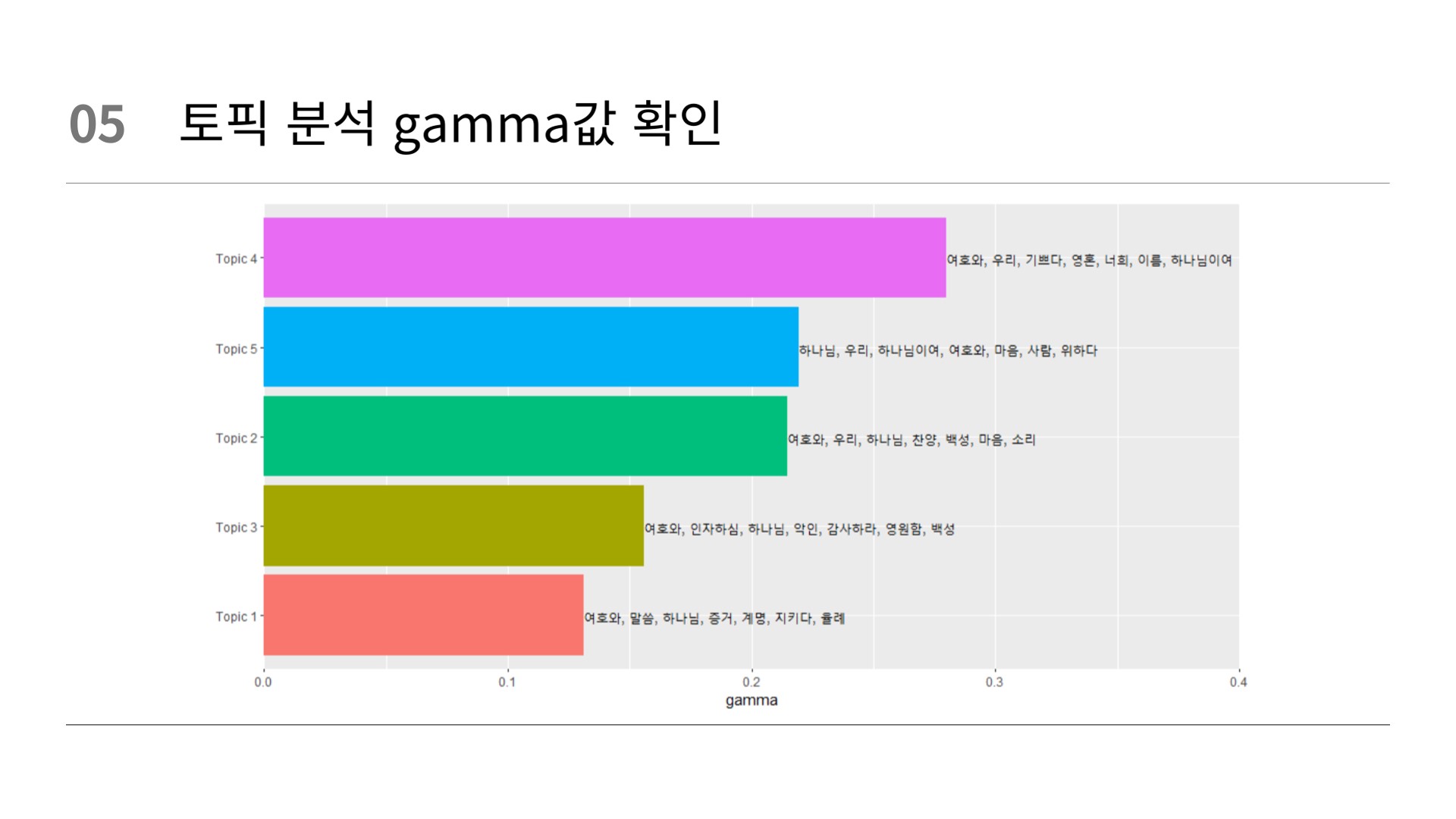
# 토픽별 단어, 문서 분포 통합
# beta를 이용해 상위 7개 단어 추출
top_terms <- word_beta %>%
arrange(beta) %>%
group_by(topic) %>%
top_n(7, beta) %>%
arrange(-beta) %>%
select(topic, term) %>%
summarise(terms = list(term)) %>%
mutate(terms = map(terms, paste, collapse = ", ")) %>%
unnest() # unnest()에서 수정함
# gamma를 이용해 토픽별 분포 확인
gamma_terms <- word_gamma %>%
group_by(topic) %>%
summarise(gamma = mean(gamma)) %>% # 토픽별 gamma 평균
arrange(desc(gamma)) %>%
left_join(top_terms, by = "topic") %>%
mutate(topic = paste0("Topic ", topic),
topic = reorder(topic, gamma))
# beta와 gamma 통합 그래프
gamma_terms %>%
ggplot(mapping = aes(x = topic,
y = gamma,
label = terms,
fill = topic)) +
geom_col(show.legend = FALSE) +
geom_text(hjust = 0) +
coord_flip() +
scale_y_continuous(expand = c(0,0),
limits = c(0, 0.4)) +
labs(x = NULL) 감성사전 불러오기
# === 감성분석 === #
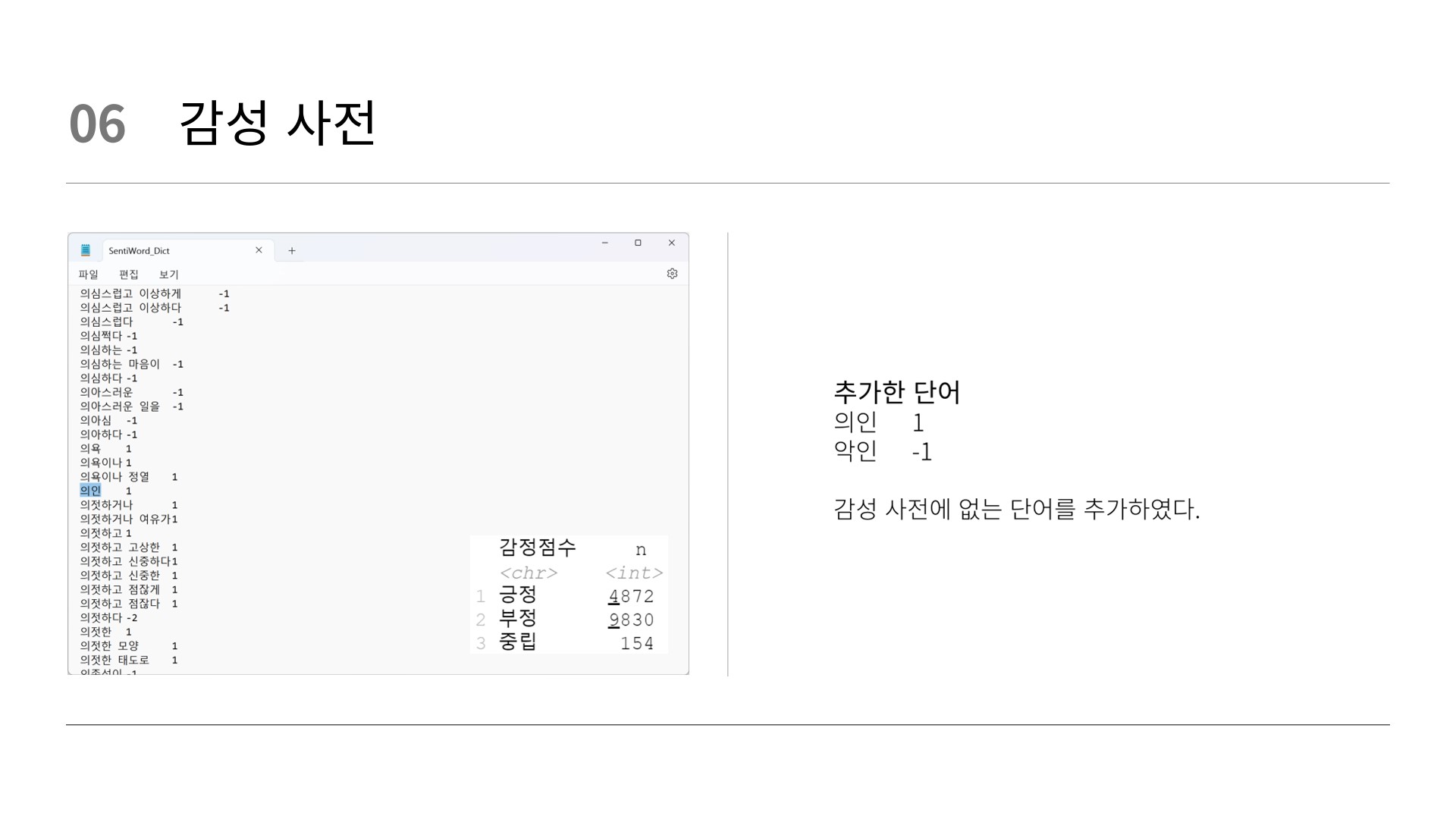
# 감성사전 불러오기
senti_dic_tb <- read_delim("Sentiword_Dict.txt",
delim = "\t",
col_names = c("word", "score"))
senti_dic_tb %>%
count(score)
# 감성사전 단어 14,845개
# 완전 부정(-2) 4799개
# 부정(-1) 5031개
# 중립(0) 154개
# 긍정(1) 2268개
# 완전 긍정(2) 2603개
senti_dic_tb %>%
mutate(감정점수 = case_when(score >= 1 ~ "긍정",
score <= -1 ~ "부정",
TRUE ~ "중립"))%>% # 긍정도 부정도 아닐 경우 중립
count(감정점수)
# 긍정 4871개
# 부정 9830개
# 중립 154개 case_when: 조건절로서 이용되며, 다중if 구문과 혼합할 수 있다.
형태소로 처리한 뒤 분석하는 방법과 그렇지 않은 경우가 있다.
'~는'로 분석할 지, '~다'로 분석할 지 선택할 수 있다.
감성 분석
# 감성분석
# 형태소 분석 없는 상태
senti_word_counts <- tm_tb %>%
# filter(!(page == 1)) %>%
select(page, verse) %>%
unnest_tokens(input = verse,
output = word) %>%
inner_join(senti_dic_tb) %>%
group_by(word) %>%
summarise(score = sum(score)) %>%
ungroup() %>%
mutate(n = abs(score)) %>%
mutate(감정점수 = case_when(score >= 1 ~ "긍정",
score <= -1 ~ "부정",
TRUE ~ "중립"))
# 긍정 단어부터 출력
senti_word_counts %>%
arrange(desc(score))
# 형태소 분석 이후 상태
senti_word_counts <- tm_tb %>%
select(page, verse) %>%
unnest_tokens(input = verse,
output = morp,
token = SimplePos09) %>% # 한글 형태소로 분리
mutate(word = str_remove(morp, "/.*$")) %>% # 형태소 정보 제거
filter(str_length(word)>=2) %>%
inner_join(senti_dic_tb) %>% # 감성사전과 매핑
group_by(word) %>%
summarise(score = sum(score)) %>%
ungroup() %>%
mutate(n = abs(score)) %>%
mutate(sentiment = case_when(score >= 1 ~ "긍정",
score <= -1 ~ "부정",
TRUE ~ "중립"))
# 형태소 분석 이후 상태 (n)
senti_word_counts <- tm_tb %>%
select(page, verse) %>%
unnest_tokens(input = verse,
output = morp,
token = SimplePos09) %>% # 한글 형태소로 분리
mutate(word = str_remove(morp, "/.*$")) %>% # 형태소 정보 제거
filter(str_length(word)>=2) %>%
inner_join(senti_dic_tb) %>% # 감성사전과 매핑
group_by(word) %>%
summarise(score = sum(score)) %>%
ungroup() %>%
mutate(n = abs(score)) %>%
mutate(sentiment = case_when(score >= 1 ~ "긍정",
score <= -1 ~ "부정",
TRUE ~ "중립"))
# 긍정 단어부터 출력
senti_word_counts %>%
arrange(desc(score))
senti_word_counts %>%
arrange(desc(n)) %>%
print(n = 30) 시각화
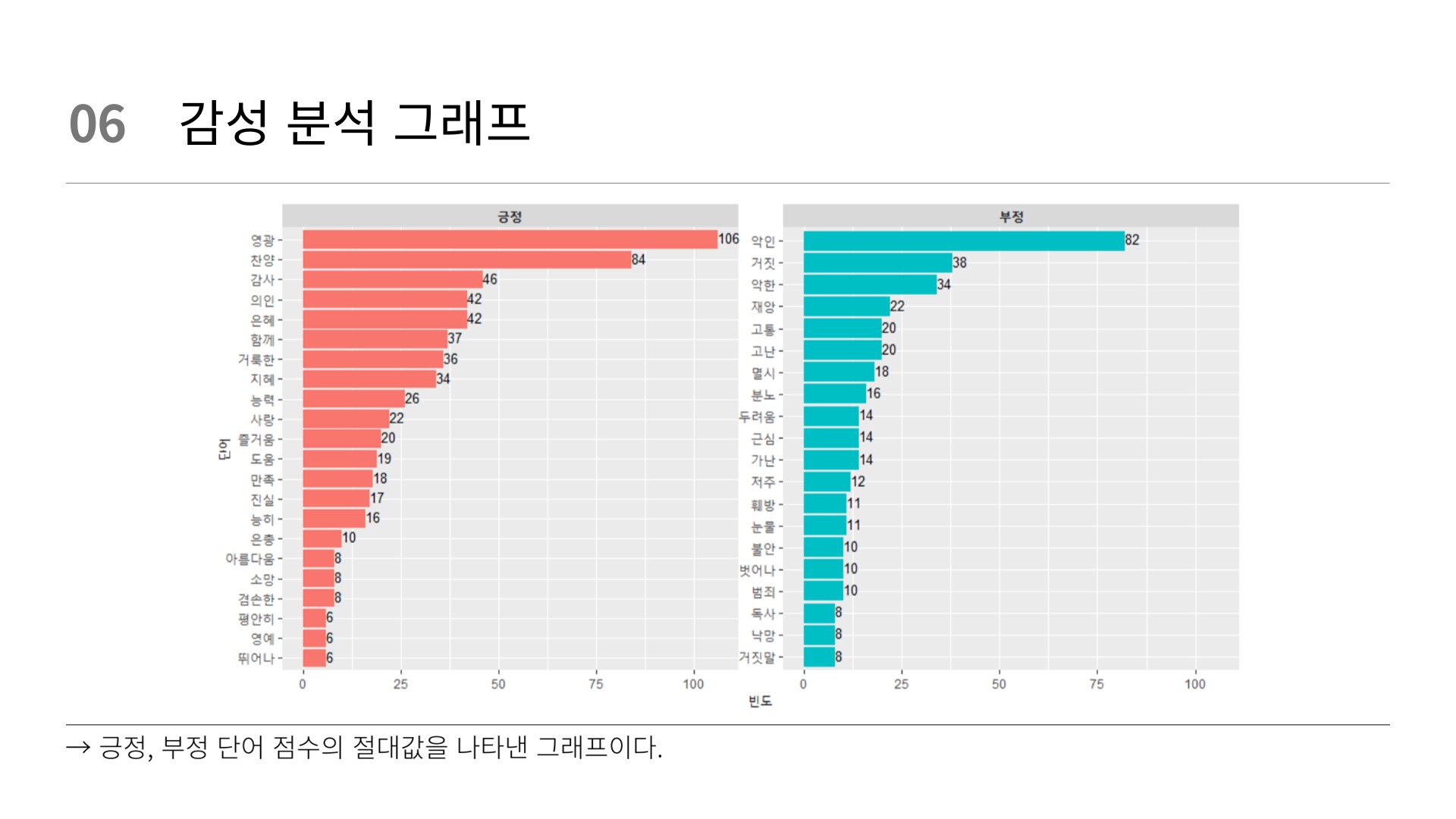
# 시각화
# word count(n)
senti_word_counts %>%
filter(!(sentiment == "중립")) %>%
group_by(sentiment) %>%
slice_max(n, n = 20) %>%
ungroup() %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(n, word, fill = sentiment)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ item1,
ncol = 3,
scales = "free") +
scale_y_reordered() +
labs(x = "점수",
y = "단어") +
theme(strip.text = element_text(face = "bold")) +
facet_wrap(~sentiment, scales = "free_y") +
geom_text(aes(label = n), vjust = 0.3, hjust = 0, color = "black", size = 3.5)
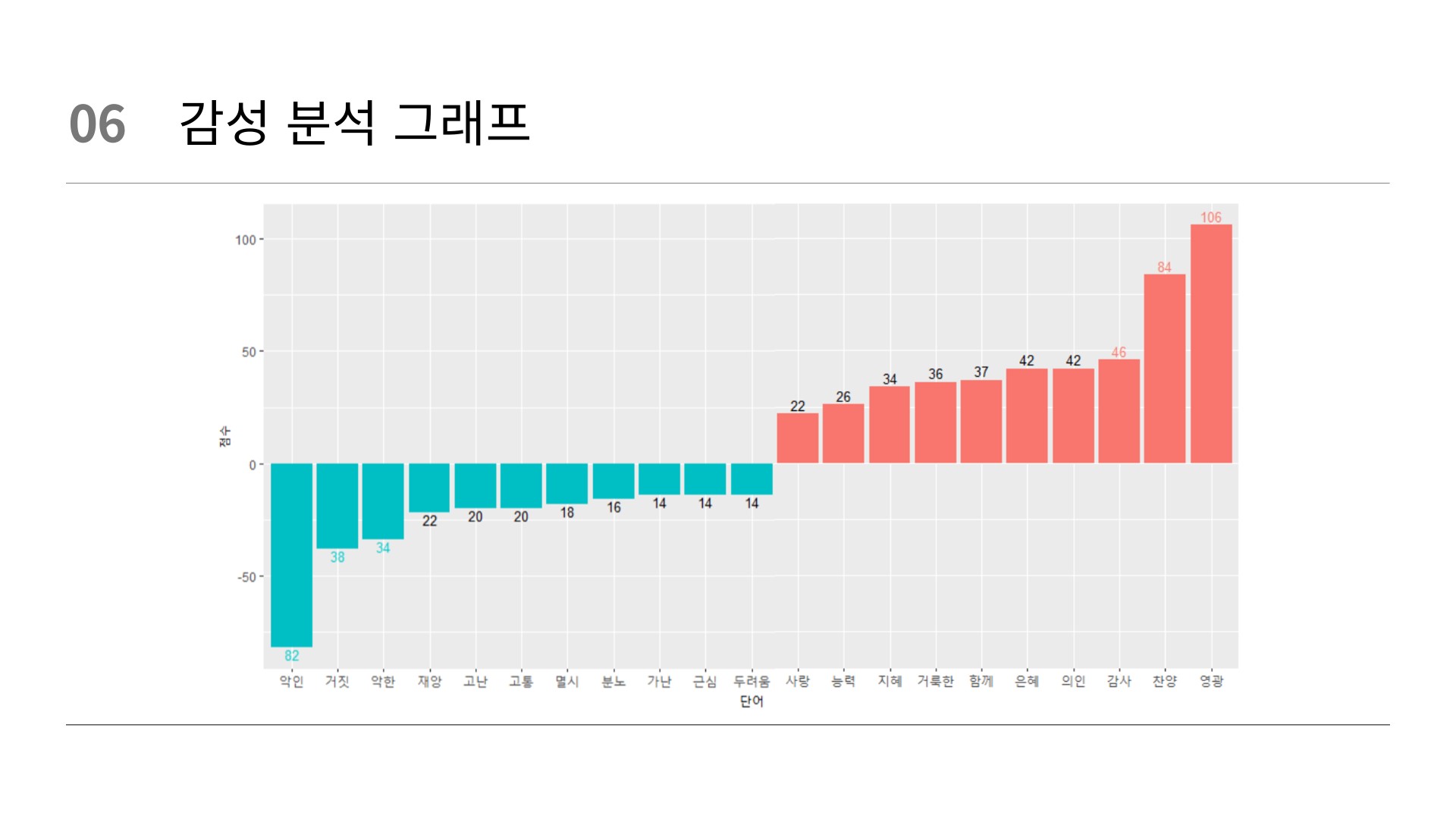
# word count(score)
senti_word_counts %>%
filter(!(sentiment == "중립")) %>%
group_by(sentiment) %>%
slice_max(n, n = 10) %>%
ungroup() %>%
mutate(word = reorder(word, score)) %>%
ggplot(aes(x = word,
y = score,
fill = score < 0)) +
labs(x = "단어",
y = "점수") +
geom_col(show.legend = FALSE) +
geom_text(aes(label = n), color = "black", size = 3.5)
senti_word_counts %>%
filter(!(sentiment == "중립")) %>%
group_by(sentiment) %>%
slice_max(n, n = 10) %>%
ungroup() %>%
mutate(word = reorder(word, score)) %>%
ggplot(aes(x = word,
y = score,
fill = score < 0)) +
labs(x = "단어",
y = "점수") +
geom_col(show.legend = FALSE) +
geom_text(aes(label = n, vjust = 1.1, color = ifelse(rank(score) >= 4, "cyan3", "black")), size = 3.5) +
scale_color_manual(values = c("cyan3", "black")) +
theme(legend.position = "none")
senti_word_counts %>%
filter(!(sentiment == "중립")) %>%
group_by(sentiment) %>%
slice_max(n, n = 10) %>%
ungroup() %>%
mutate(word = reorder(word, score)) %>%
ggplot(aes(x = word,
y = score,
fill = score < 0)) +
labs(x = "단어",
y = "점수") +
geom_col(show.legend = FALSE) +
geom_text(aes(label = n, vjust = -0.3, color = ifelse(rank(-score)>= 4 , "salmon", "black")), size = 3.5) +
scale_color_manual(values = c("salmon", "black")) +
theme(legend.position = "none")
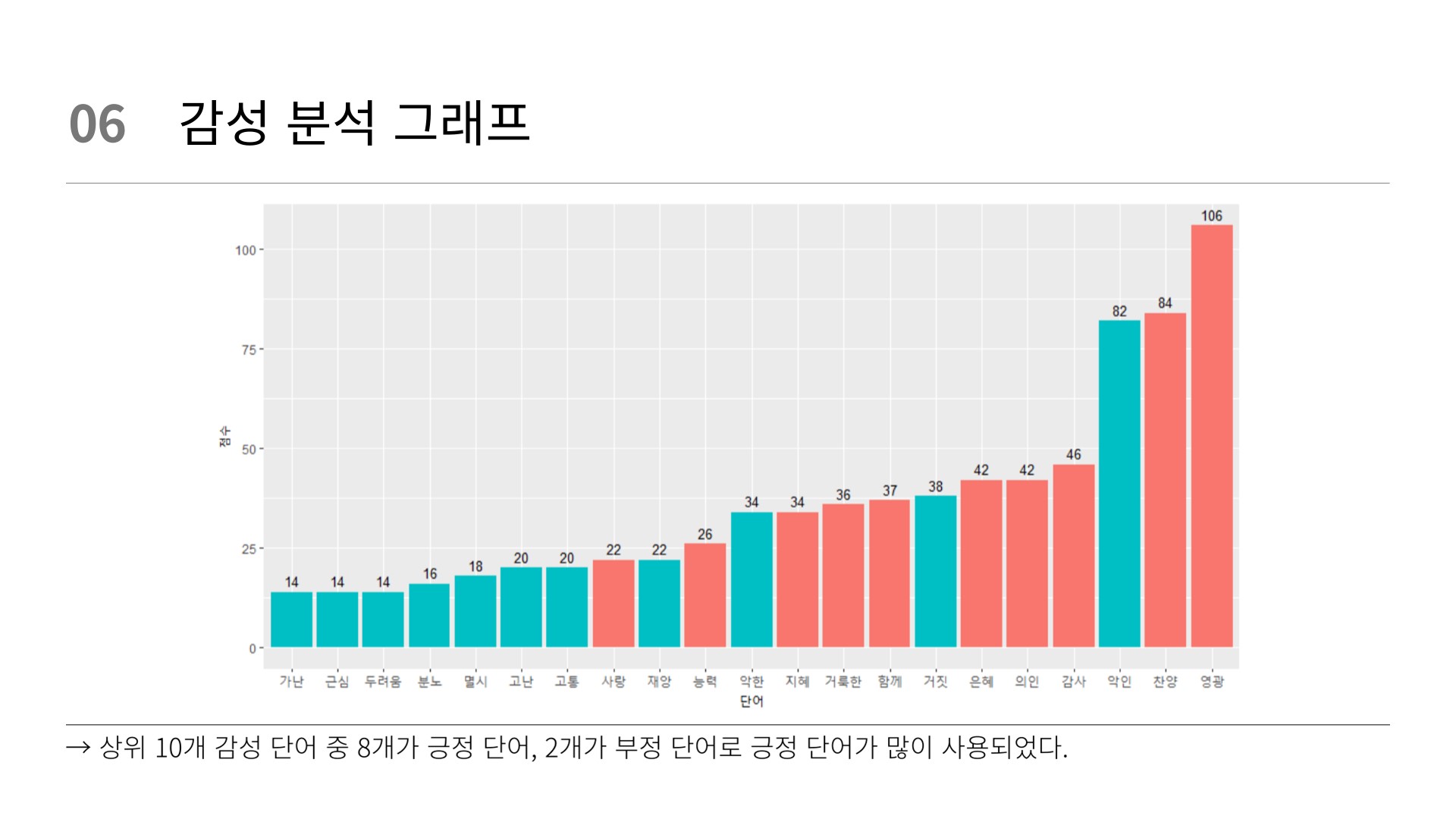
# word count(교차)
senti_word_counts %>%
filter(!(sentiment == "중립")) %>%
group_by(sentiment) %>%
slice_max(n, n = 10) %>%
ungroup() %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(x = word,
y = n,
fill = score < 0)) +
labs(x = "단어",
y = "점수") +
geom_col(show.legend = FALSE) +
geom_text(aes(label = n), vjust = -0.5, color = "black", size = 3.5)
# wordcolud
set.seed(123)
senti_word_counts %>%
filter(!(sentiment == "중립")) %>%
group_by(sentiment) %>%
# slice_max(n, n = 10) %>%
ungroup() %>%
ggplot(mapping = aes(label = word,
size = n,
color = sentiment,
angle_group = score < 0)) +
geom_text_wordcloud_area() +
scale_size_area(max_size = 30) +
theme_minimal()
# wordcolud(구분)
set.seed(123)
senti_word_counts %>%
filter(!(sentiment == "중립")) %>%
group_by(sentiment) %>%
slice_max(n, n = 20) %>%
ggplot(mapping = aes(label = word,
size = n,
color = sentiment)) +
geom_text_wordcloud_area() +
scale_size_area(max_size = 30) +
facet_wrap(~ sentiment)